
カラム分析とデータマスキング操作でサポートされる文字タイプ
Talend Data PreparationまたはtDataMaskingコンポーネントを使用してデータをマスキングする場合、入力データ内の各文字は、サポートされるUnicode範囲内の同じ文字タイプの文字にマスキングされます。
Talend Studioでカラム分析を作成する場合は、アジア系の文字に 東アジアパターン頻度または東アジアパターン低頻度インジケーターを使用して、データのコンテンツ、ストラクチャー、およびクオリティを定義できます。
次のテーブルは、サポートされる文字タイプおよび関連するUnicode範囲(バージョン11.0)を説明しています。
詳細は、documentation for the Unicode Standard (英語のみ)とcharacter code charts (英語のみ)をご覧ください。
| 文字タイプ | Unicode範囲(バージョン11.0) | 対応する文字 |
|---|---|---|
| ラテン数字 (英語のみ) | [0030-0039] | [0-9] |
| ラテン小文字 | [0061-007A] (英語のみ) [00DF-00F6] [00F8-00FF] (英語のみ) | [a-z] [ß-ö] [ø-ÿ] |
| ラテン大文字 | [0041-005A] (英語のみ) [00C0-00D6] [00D8-00DE] (英語のみ) | [A-Z] [À-Ö] [Ø-Þ] |
| 全角ラテン数字 (英語のみ) | [FF10-FF19] | [0-9] |
| 全角ラテン小文字 (英語のみ) | [FF41-FF5A] | [a-z] |
| 全角ラテン大文字 (英語のみ) | [FF21-FF3A] | [A-Z] |
| ひらがな (英語のみ) | [3041-3096] 30FC 309D 309E | [ぁ-ゖ] ー ゝ ゞ |
| 半角カタカナ (英語のみ) | [FF66-FF9D] | [ヲ-ン] |
| 全角カタカナ (英語のみ) | [30A1-30FA] 30FC 30FD 30FE | [ァ-ヺ] ー ヽ ヾ |
| 表音拡張 (英語のみ): [31F0-31FF] | [ㇰ-ㇿ] | |
| 漢字 | CJK拡張A (英語のみ): [4E00-9FEF] [3400-4DB5] | [一-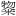 ] [㐀-䶵] ] [㐀-䶵] |
| CJK拡張B (英語のみ): [20000-2A6D6] | [𠀀-𪛖] | |
| CJK拡張C (英語のみ): [2A700-2B734] | [𪜀-𫜴] | |
| CJK拡張D (英語のみ): [2B740-2B81D] | [𫝀-𫠝] | |
| CJK拡張E (英語のみ): [2B820-2CEA1] | [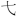 - - ] ] |
|
| CJK拡張F (英語のみ): [2CEB0-2EBE0] | [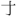 - - ] ] |
|
| CJK互換漢字 (英語のみ): [F900-FA6D] [FA70-FAD9] | [豈-舘] [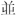 - -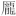 ] ] |
|
| CJK互換漢字補助 (英語のみ): [2F800-2FA1D] | [ - -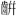 ] ] |
|
| 康熙部首 (英語のみ): [2F00-2FD5] | [⼀-⿕] | |
| CJK部首補助 (英語のみ): [2E80-2E99] [2E9B-2EF3] | [⺀-⺙] [⺛-⻳] | |
| CJKの記号および句読点 (英語のみ): [3005-3005] [3007-3007] [3021-3029] [3038-303B] | [々-々] [〇-〇] [〡-〩] [〸-〻] | |
| ハングル (英語のみ) | [AC00-D7AF] | [가-] |