
Creating the match rule to group similar records
Procedure
-
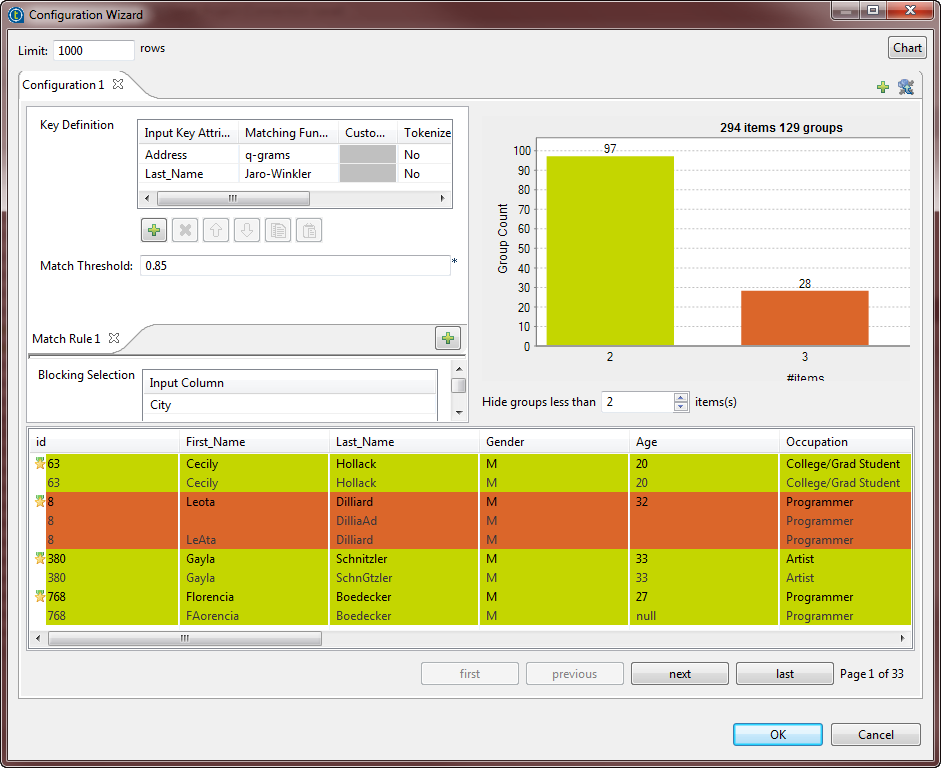
Double-click tMatchGroup to open the configuration wizard
where you can define the match rule.
-
Double-click tMap to open its editor.

-
When data comes from different sources and if the input schema
has a column which holds the source names, map the source column to TDS_SOURCE.
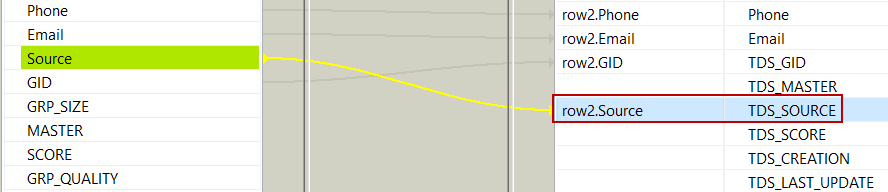
If you do not specify the source names, Source 1, Source 2 and so on are added by default.
If you specify the same name in multiple sources of the same tasks, the suffixes -1, -2 and so on are added by default. For example, if you create a task with three sources SAP, the source names in Talend Data Stewardship are displayed as SAP, SAP - 1, SAP - 2.
You can also compute dynamically the trust scores of specific records if you provide them at the task source level and map them to the TDS_RATING output column in tDataStewardshipTaskOutput. These trust scores override the scores defined at campaign creation, if any.
Make sure that the source names in the input file do not contain dots and that they do not start with a dollar sign.