
Configuring the tDataShuffling component
Procedure
-
Double-click tDataShuffling to display the
Basic settings view and define the component
properties.
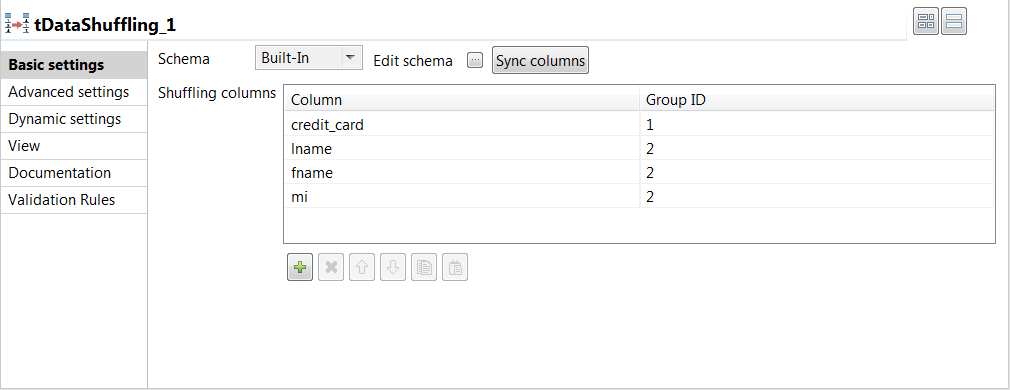
-
Click the Advanced settings tab.
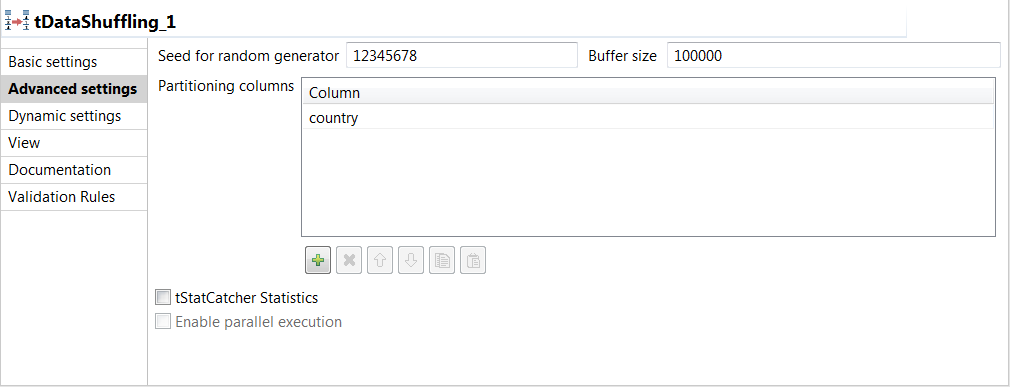 In the Partitioning columns table, click the [+] button to add one row.The Job will shuffle the original data rows sharing the same value for the partitioning columns.In the above example, the component is configured to apply the shuffling process to the rows sharing the same value for the country column.
In the Partitioning columns table, click the [+] button to add one row.The Job will shuffle the original data rows sharing the same value for the partitioning columns.In the above example, the component is configured to apply the shuffling process to the rows sharing the same value for the country column.