
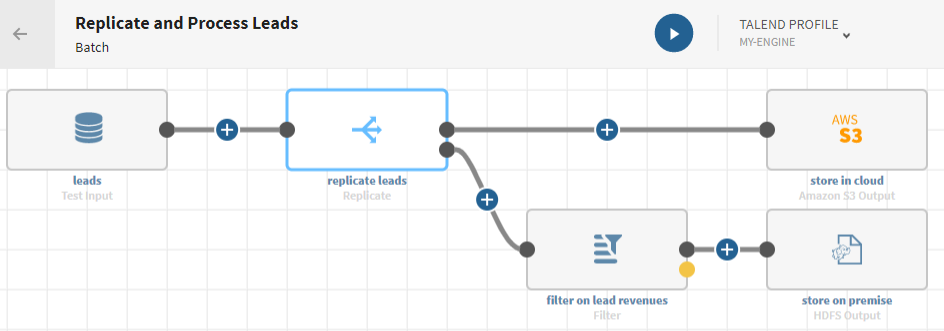
Replizieren einer Liste mit Leads und unterschiedliches Verarbeiten der zwei Ausgabe-Flows
Vorbereitungen
-
Sie haben zuvor eine Verbindung zu dem System erstellt, in dem die Quelldaten gespeichert sind.
In diesem Beispiel eine Verbindung zu einer Datenbank.
-
Sie haben zuvor den Datensatz hinzugefügt, der die Quelldaten enthält.
Laden Sie folgende Datei herunter und extrahieren Sie sie: filter-python-customers.zip. Sie enthält Lead-Daten, u. a. ID, Name, Umsatz usw.
-
Sie haben außerdem die Verbindung und den zugehörigen Datensatz erstellt, der die verarbeiteten Daten aufnehmen soll.
In diesem Beispiel eine in Amazon S3 und eine in HDFS gespeicherte Datei.
Prozedur
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Replicate (Replizieren) zur Pipeline hinzu. Daraufhin wird der Flow dupliziert und das Konfigurationsfenster geöffnet.
und fügen Sie einen Prozessor vom Typ Replicate (Replizieren) zur Pipeline hinzu. Daraufhin wird der Flow dupliziert und das Konfigurationsfenster geöffnet.
-
Klicken Sie auf neben dem untersten Element ADD DESTINATION (ZIEL HINZUFÜGEN) für die Pipeline und fügen Sie einen Prozessor vom Typ Filter hinzu.
-
(Optional) Sehen Sie sich die Vorschau des Prozessors vom Typ Filter an, um zu prüfen, wie Ihre Daten nach der Filterung aussehen.
Example
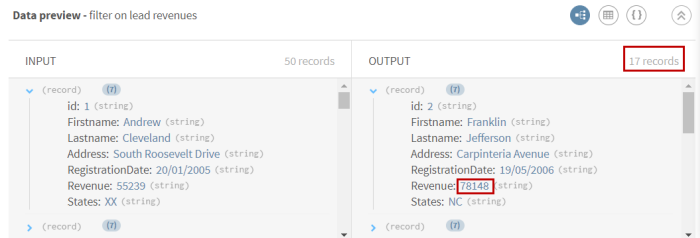
Ergebnisse
Ihre Pipeline wird ausgeführt, die Datensätze werden dupliziert und gefiltert und die Ausgabe-Flows an die von Ihnen angegebenen Zielsysteme gesendet.