
Verarbeiten von Zeichenfolgen über Getreideernten
Vorbereitungen
-
Sie haben zuvor eine Verbindung zu dem System erstellt, in dem die Quelldaten gespeichert sind.
In diesem Beispiel eine Verbindung zu Amazon S3.
-
Sie haben zuvor den Datensatz hinzugefügt, der die Quelldaten enthält.
Laden Sie folgende Datei herunter: string-crops.csv. Sie enthält einen Datensatz mit Daten zu Ernten in Mali mit Erntetyp, Produktionswert, abgeernteten Gebieten usw.
-
Sie haben außerdem die Verbindung und den zugehörigen Datensatz erstellt, der die verarbeiteten Daten aufnehmen soll.
In diesem Beispiel ein im gleichen S3-Bucket gespeicherter Datensatz.
Prozedur
-
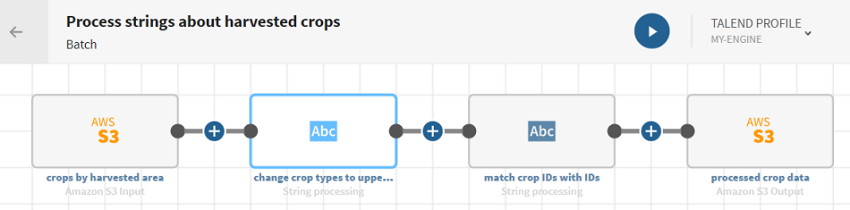
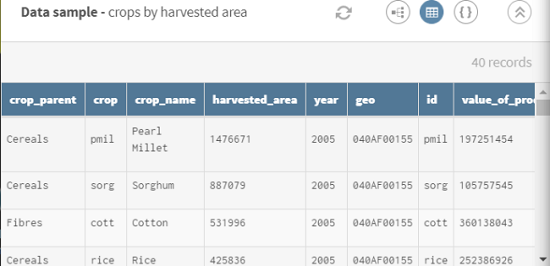
Klicken Sie auf ADD SOURCE (QUELLE HINZUFÜGEN), um ein Fenster zu öffnen, in dem Sie die Quelldaten, in diesem Fall Daten zur Getreideernte in Mali im Jahr 2005, auswählen können.
Example
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Strings (Zeichenfolgen) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
und fügen Sie einen Prozessor vom Typ Strings (Zeichenfolgen) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
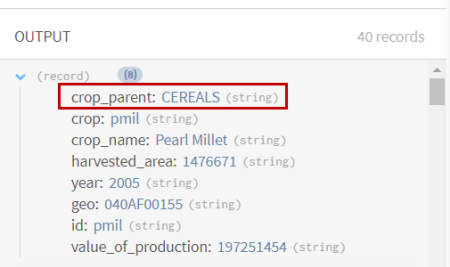
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
Sehen Sie sich die Vorschau des Prozessors an, um die Daten vor dem Vorgang mit denjenigen nach dem Vorgang zu vergleichen.
-
Klicken Sie auf und fügen Sie einen weiteren Prozessor vom Typ Strings (Zeichenfolgen) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
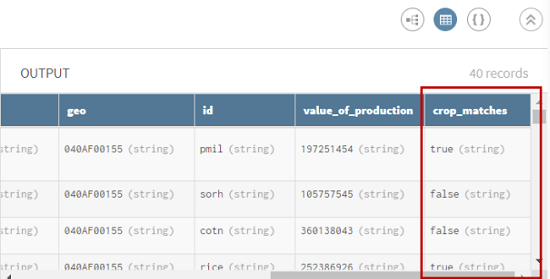
Sehen Sie sich die Vorschau des Prozessors an, um die Daten vor dem Vorgang mit denjenigen nach dem Vorgang zu vergleichen. Sie sehen jetzt die neue Spalte crop_matches (Getreide_Übereinstimmungen), in der die genauen Übereinstimmungen den Wert true und nicht übereinstimmende IDs den Wert false aufweisen.
Ergebnisse
Ihre Pipeline wird ausgeführt, die ausgewählten Zeichenfolgen werden verarbeitet und der Ausgabe-Flow an das von Ihnen angegebene S3-Bucket gesendet.