
Erkennen von Datentypen und semantischen Typen
Beim Hinzufügen von Datensätzen schlägt Talend Data Preparation automatisch für jede Spalte die Datentypen bzw. semantischen Typen vor, die den Daten jeweils am besten entsprechen.
Erkennen semantischer Typen
Um den Prozentsatz für jeden semantischen Typ anzuzeigen, klicken Sie in der Sample-Ansicht Ihres Datensatzes auf das Symbol ![]() .
.
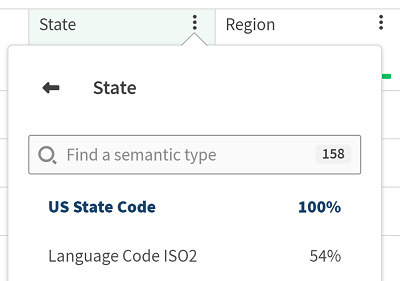
Diese Funktion ist auch in der Hierarchieansicht (Hierarchy) verfügbar.
Wie wird der Prozentsatz berechnet?
-
Ein Prozentsatz entspricht der Anzahl der Werte, die mit dem semantischen Typ übereinstimmen. Max. zugewiesener Wert: 100 %.
Um zu bestimmen, ob ein Wert einem semantischen Typ entspricht, greift die Datenerkennung auf den Typ des semantischen Typs zurück:
- Wörterbuch: Entspricht der Wert einem Wert aus dem Wörterbuch? Satzzeichen, Groß-/Kleinschreibung, Leerzeichen und Akzente werden ignoriert.
- Regular expression (Regulärer Ausdruck): Entspricht der Wert dem regulären Ausdruck?
- Compound (Zusammengesetzter Wert): Wird der Wert in mindestens einem untergeordneten Element erkannt?Ein zusammengesetzter Typ entspricht einer Gruppe vorhandener semantischer Typen, die als untergeordnete Elemente bezeichnet werden.
Bei einer positiven Antwort wird der Wert als gültig eingestuft.
- Der andere Prozentsatz verweist auf die Ähnlichkeit zwischen Spaltenname und Name des semantischen Typs. Max. zugewiesener Wert: 10 %. Für den Vergleich der Namen:Der maximale Prozentsatz ist 100 %. Wenn alle Werte einem semantischen Typ entsprechen und der Spaltenname mit dem Namen des semantischen Typs übereinstimmt, ist das Ergebnis ebenfalls 100 %.
- Wird der Levenshtein-Algorithmus verwendet. Wird die Mindestanzahl an Bearbeitungen (Einfügen, Löschen oder Ersetzen) berechnet, die für die Transformation einer Zeichenfolge in eine andere erforderlich ist.
- Werden Groß-/Kleinschreibung und Akzente ignoriert.
- Wenn die Zeichenfolgen Leerzeichen enthalten, wird die Wortreihenfolge ignoriert. Beispiel: US Phone und Phone US werden als identisch eingestuft.
Anzeigen der Qualitätsleiste
- In der Rasteransicht (Grid):

- In der Hierarchieansicht (Hierarchy):

Der Prozentsatz der gültigen Werte kann unter dem Ergebnis der Datenerkennung liegen. Das kann in folgenden Fällen vorkommen:
- Die Validierungsregel ist einschränkender als der semantische Typ. In diesem Fall entsprechen die Werte denjenigen des semantischen Typs, aber gemäß der Validierungsregel stimmen die Werte nicht überein, beispielsweise in Bezug auf die Groß-/Kleinschreibung oder Satzzeichensetzung.
- Die Übereinstimmung des Spaltennamens und des Namens des semantischen Typs ergibt 100 % für den semantischen Typ. In diesem Fall werden in der Qualitätsleiste 90 % und 100 % gültiger Werte angegeben.
Erkennen nativer Datentypen
| Nativer Datentyp | Beschreibung | Beispiel |
|---|---|---|
| Text | Zeichenfolgentext | username |
| Integer (Ganzzahl) | Numerischer Wert | 123 |
| Decimal (Dezimalwert) | Numerischer Dezimalwert | 1.26 |
| Date (Datum) | Datum, einschließlich Tag, Monat und Jahr | 11/08/2022 |
| Time (Uhrzeit) | Tageszeit | 11am |
| Timestamps (Zeitstempel) | Datum und Uhrzeit | 11/08 11:00 |
| Boolean (Boolescher Wert) | Antworten mit dem Wert True oder False | True |
- Ist der Wert leer?
- Ist der Wert vom Typ „Boolean“ (Boolescher Wert)? True und False sind die einzigen Werte, die als boolescher Wert eingestuft werden.
- Ist der Wert vom Typ „Integer“ (Ganzzahl)?
- Ist der Wert vom Typ „Decimal“ (Dezimalwert)?
- Ist der Wert vom Typ „Date“ (Datum)?
- Wenn der Wert keinen der oben genannten Typen aufweist, wird er als Text-Wert eingestuft.
Da die Prüfung ein inkrementaler Prozess ist, weist ein Wert nur jeweils einen Typ auf. Beispiel: Der Wert 5 ist vom Typ Integer (Ganzzahl). Er wird nicht als Text eingestuft.