Load
L'istruzione LOAD carica i campi da un file, dai dati definiti nello script, da una tabella caricata in precedenza, da una pagina Web, dal risultato di un'istruzione SELECT seguente o dalla generazione automatica di dati. È anche possibile caricare dati da connessioni di analisi.
Sintassi:
LOAD [ distinct ] fieldlist
[( from file [ format-spec ] |
from_field fieldassource [format-spec]|
inline data [ format-spec ] |
resident table-label |
autogenerate size ) |extension pluginname.functionname([script] tabledescription)]
[ where criterion | while criterion ]
[order by orderbyfieldlist ]
Argomenti:
| Argomento | Descrizione |
|---|---|
| distinct | È possibile utilizzare distinct come predicato se si desidera caricare solo record univoci. Se ci sono record duplicati, verrà caricata la prima istanza. Se si utilizzano caricamenti precedenti, è necessario inserire distinct nella prima istruzione di caricamento, dal momento che distinct ha effetto solo sulla tabella di destinazione. |
| fieldlist | fieldlist ::= ( * | field{, * | field } ) Un elenco di campi da caricare. L'utilizzo del carattere * come elenco dei campi indica tutti i campi della tabella. field ::= ( fieldref | expression ) [as aliasname ]La definizione di campo deve sempre contenere un valore letterale, un riferimento a un campo esistente o un'espressione. fieldref ::= ( fieldname |@fieldnumber |@startpos:endpos [ I | U | R | B | T] )fieldname è un testo che è identico al nome di un campo nella tabella. Tenere presente che il nome di campo deve essere racchiuso da virgolette doppie o parentesi quadre se, ad esempio, contiene spazi. Talvolta i nomi dei campi non sono disponibili in modo esplicito. Verrà quindi utilizzata una notazione differente: @fieldnumber rappresenta il numero di campo di un file tabellare delimitato. Deve essere un intero positivo preceduto da "@". La numerazione viene sempre eseguita partendo da 1 fino al numero di campi presenti. @startpos:endpos rappresenta le posizioni di inizio e di fine di un campo in un file con record a lunghezza fissa. Le posizioni devono essere entrambe numeri interi positivi. I due valori numerici devono essere preceduti dal simbolo "@" e separati da due punti. La numerazione viene sempre eseguita partendo da 1 fino al numero di posizioni presenti. Nell'ultimo campo n viene utilizzato come posizione finale.
expression può essere una funzione numerica o una funzione stringa basata su uno o molti altri campi della stessa tabella. Per ulteriori informazioni, vedere la sintassi delle espressioni. |
| from | from viene utilizzato se i dati devono essere caricati da un file mediante una connessione dati di una cartella o di un file Web file ::= [ path ] filename Esempio: 'lib://Table Files/' Se tale percorso viene omesso, Qlik Sense ricerca il file nella directory specificata dall'istruzione Directory. Se non è presente alcuna istruzione Directory, Qlik Sense eseguirà la ricerca nella directory di lavoro, C:\Users\{user}\Documents\Qlik\Sense\Apps. Nota informaticaIn un'installazione server di Qlik Sense, la directory di lavoro è specificata in Qlik Sense Repository Service e, per impostazione predefinita, è C:\ProgramData\Qlik\Sense\Apps. Per ulteriori informazioni, vedere la Guida di Qlik Management Console. filename può contenere caratteri speciali nello standard DOS ( * e ? ). Tutti i file corrispondenti verranno caricati nella directory specificata. format-spec ::= ( fspec-item { , fspec-item } )La specifica del formato è costituita da un elenco di più voci di specifica del formato, racchiuse tra parentesi. Voci per la specifica del formato Nota di suggerimentoÈ possibile utilizzare la specifica di formato URL is per sostituire l'URL di una connessione dati di un file Web, ad esempio se è necessario creare un URL dinamico in base ad altri dati caricati. Modalità di script legacy Nella modalità di creazione degli script legacy sono supportati anche i seguenti formati di percorso:
|
| from_field | from_field viene utilizzato nel caso in cui i dati devono essere caricati da un campo caricato in precedenza. fieldassource::=(tablename, fieldname) Il campo è il nome del valore di tablename e fieldname caricato in precedenza. format-spec ::= ( fspec-item {, fspec-item } )La specifica del formato è costituita da un elenco di più voci di specifica del formato, racchiuse tra parentesi. Per ulteriori informazioni, vedere Voci per la specifica del formato. Nota informaticafrom_field supporta solo le virgole come delimitatore di elenco quando si separano campi nelle tabelle. |
| inline | inline viene utilizzato quando i dati devono essere immessi direttamente nello script e non caricati da un file. data ::= [ text ] I dati immessi mediante una clausola inline devono essere racchiusi tra virgolette doppie o tra parentesi quadre. Il testo tra parentesi o virgolette viene interpretato allo stesso modo del contenuto di un file. Pertanto, quando si desidera modificare o immettere una nuova riga in un file di testo, è necessario eseguire questa operazione anche nel testo di una clausola inline, ad esempio premendo il tasto INVIO mentre si digita lo script. Il numero di colonne è definito nella prima riga. format-spec ::= ( fspec-item {, fspec-item } )La specifica del formato è costituita da un elenco di più voci di specifica del formato, racchiuse tra parentesi. Per ulteriori informazioni, vedere Voci per la specifica del formato. |
| resident | resident viene usato se i dati devono essere caricati da una tabella caricata in precedenza. table label è un'etichetta che precede le istruzioni LOAD o SELECT che hanno creato la tabella originale. L'etichetta dovrà essere indicata con i due punti finali. |
| autogenerate | autogenerate viene utilizzato se i dati devono essere automaticamente generati da Qlik Sense. size ::= number Number è un numero intero e indica il numero di record che da generare. L'elenco di campi non deve contenere espressioni che richiedono dati provenienti da una sorgente dati esterna o da una tabella caricata in precedenza, a meno che non si faccia riferimento a un singolo valore di campo in una tabella caricata in precedenza con la funzione Peek. |
| extension | È possibile caricare dati da connessioni di analisi. È necessario utilizzare la clausola extension per chiamare una funzione definita nel plug-in SSE (Server-Side Extension) o per valutare uno script. È possibile inviare una singola tabella al plug-in SSE, che restituisce una singola tabella di dati. Se il plug-in non specifica i nomi dei campi restituiti, i campi saranno denominati Field1, Field2 e così via. Extension pluginname.functionname( tabledescription );
Gestione dei tipi di dati nella definizione dei campi della tabella I tipi di dati sono riconosciuti automaticamente nelle connessioni di analisi. Se i dati non hanno valori numerici e hanno almeno una stringa di testo non NULL, il campo è considerato di tipo testo. In tutti gli altri casi è considerato di tipo numerico. È possibile forzare il tipo di dati racchiudendo il nome del campo in String() o Mixed().
String() o Mixed() non possono essere utilizzati esternamente alle definizioni dei campi della tabella extension e non è possibile utilizzare altre funzioni di Qlik Sense nella definizione di un campo della tabella. Ulteriori informazioni sulle connessioni di analisi Prima di poter utilizzare le connessioni di analisi, è necessario configurarle. Qlik Sense Enterprise: Creazione di una connessione di analisi (solo in lingua inglese) Qlik Sense Desktop: Configurazione di connessioni di analisi in Qlik Sense Desktop Ulteriori informazioni sulle connessioni di analisi sono disponibili nel repository di GitHub. qlik-oss/server-side-extension |
| where | where è una clausola utilizzata per dichiarare se un record deve essere incluso o meno nella selezione. La selezione viene inclusa se criterion è True. criterion è un'espressione logica. |
| while | while è una clausola che specifica se un record deve essere letto ripetutamente. Viene letto lo stesso record finché criterion è True. Per risultare utile, una clausola while deve generalmente includere la funzione IterNo( ). criterion è un'espressione logica. |
| group by | group by è una clausola usata per definire su quali campi devono essere aggregati (raggruppati) i dati. I campi di aggregazione devono essere inclusi in qualche modo nelle espressioni caricate. Nessun altro campo tranne i campi di aggregazione può essere usato al di fuori delle funzioni di aggregazione nelle espressioni caricate. groupbyfieldlist ::= (fieldname { ,fieldname } ) |
| order by | order by è una clausola utilizzata per ordinare i record di una tabella residente prima che vengano elaborati da un’istruzione load. La tabella residente può essere ordinata su uno o più campi, in modo crescente o decrescente. L’ordinamento viene eseguito innanzitutto in base ai valori numerici e secondariamente in base all'ordine di confronto nazionale. Questa clausola può essere utilizzata solamente quando la sorgente dati è una tabella residente. I campi di ordinamento specificano il campo in base al quale viene ordinata la tabella residente. Il campo può essere specificato da un nome o dal suo numero nella tabella residente (il primo campo è il numero 1). orderbyfieldlist ::= fieldname [ sortorder ] { , fieldname [ sortorder ] } sortorder è asc per crescente o desc per decrescente. Se sortorder non è specificato, viene utilizzato asc. fieldname, path, filename e aliasname sono stringhe di testo che rappresentano ciò che implica il loro rispettivo nome. Qualsiasi campo presente nella tabella sorgente può essere utilizzato come fieldname. Tuttavia, i campi creati mediante la clausola as (aliasname) non appartengono all'ambito e non possono essere utilizzati all'interno della stessa istruzione load. |
Se non viene specificata alcuna sorgente dati mediante una clausola from, inline, resident, from_field, extension o autogenerate, i dati verranno caricati dal risultato dell'istruzione SELECT o LOAD immediatamente successiva. L’istruzione successiva non dovrà avere un prefisso.
Caricamento di dati da una tabella caricata in precedenza
Esempi:
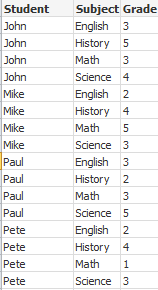
In questo esempio è presente un file di input Grades.csv contenente i voti per ciascuno studente raccolti in un singolo campo:
Student,Grades
Mike,5234
John,3345
Pete,1234
Paul,3352
I voti, in una scala da 1 a 5 , rappresentano le materie Math, English, Science e History. È possibile suddividere i voti in valori separati leggendo i record più volte con una clausola while, utilizzando la funzione IterNo( ) come contatore. Durante ciascuna lettura, il voto viene estratto con la funzione Mid e memorizzato in Grade, mentre la materia viene selezionata utilizzando la funzione pick e memorizzata in Subject. La clausola finale while contiene il test per verificare che siano stati letti tutti i voti (in questo caso quattro per studente), il che significa che deve essere letto il record dello studente successivo.
MyTab:
LOAD Student,
mid(Grades,IterNo( ),1) as Grade,
pick(IterNo( ), 'Math', 'English', 'Science', 'History') as Subject from Grades.csv
while IsNum(mid(Grades,IterNo(),1));
Il risultato è una tabella contenente i seguenti dati: