Load
LOAD ステートメントは、ファイル、スクリプトで定義されたデータ、事前にロードされたテーブル、Web ページ、後続の SELECT ステートメントの結果、または自動生成されたデータから項目をロードします。 分析接続からデータをロードすることもできます。
構文:
LOAD [ distinct ] fieldlist
[( from file [ format-spec ] |
from_field fieldassource [format-spec]|
inline data [ format-spec ] |
resident table-label |
autogenerate size ) |extension pluginname.functionname([script] tabledescription)]
[ where criterion | while criterion ]
[order by orderbyfieldlist ]
引数:
| 引数 | 説明 |
|---|---|
| distinct | 一意のレコードのみをロードする場合、distinct を述語として使用できます。重複するレコードがある場合は、1 つめのインスタンスがロードされます。 先行する LOAD を使用している場合、distinct はロード先のテーブルにのみ反映されるので、Load ステートメントの先頭に distinct を配置する必要があります。 |
| fieldlist | fieldlist ::= ( * | field{, * | field } ) ロードする項目のリスト。項目リストとして * を使用すると、テーブルのすべての項目が指定されます。 field ::= ( fieldref | expression ) [as aliasname ]項目定義には、リテラル、既存項目への参照、または数式を含める必要があります。 fieldref ::= ( fieldname |@fieldnumber |@startpos:endpos [ I | U | R | B | T] )fieldname は、テーブル内の項目名と同じテキストです。項目名にスペースなどが含まれる場合は、ストレート二重引用符または角括弧で囲む必要があります。明示的に表現できない項目名については、次のような表記規則を使用します。 @fieldnumber は、区切り記号付きテーブル ファイルの項目番号を表します。「@」が前に付いた正の整数でなければなりません。常に 1 から項目の数まで、番号が振られています。 @startpos:endpos は、固定長レコードが含まれるファイル内の項目の開始および終了位置を表します。位置はどちらも正の整数でなければなりません。2 つの番号の前に「@」を付け、コロン (:) で区切る必要があります。常に 1 から位置の数までの番号が付けられます。最後の項目で、n は終了位置として使用されます。
expression は、同じテーブルにある 1 つまたは複数の項目に基づいた数値関数または文字列関数です。詳細については、数式の構文を参照してください。 |
| from | from は、データをフォルダーまたは Web ファイル データ接続を使用するファイルからロードする必要がある場合に使用します file ::= [ path ] filename 'lib://Table Files/' パスを省略すると、Qlik Sense は、Directory ステートメントで指定されたディレクトリのファイルを検索します。Directory ステートメントがない場合、Qlik Sense は作業ディレクトリ C:\Users\{user}\Documents\Qlik\Sense\Apps を検索します。 情報メモQlik Sense の場合、作業ディレクトリは Qlik Sense Repository Service で指定されています。これはデフォルトで、C:\ProgramData\Qlik\Sense\Apps です。詳細については、Qlik Management Console ヘルプを参照してください。 filename には、標準の DOS ワイルドカード文字 (* および ?) が含まれる場合があります。これにより、指定されたディレクトリ内にあるすべての一致ファイルがロードされます。 format-spec ::= ( fspec-item { , fspec-item } )この書式指定は、括弧に囲まれた複数の書式指定アイテムのリストで構成されます。 ヒント メモURL is 書式指定を使用して、Web ファイル データ接続の URL を上書きすることができます。例えば、ロードされた別のデータに基づく動的 URL を作成する必要のある場合が該当します。 レガシー スクリプティング モード レガシー スクリプト モードは、次のパス形式にも対応しています。
|
| from_field | 事前にロードされた項目からデータをロードする場合は、from_field を使用します。 fieldassource::=(tablename, fieldname) 項目は、事前にロードされた tablename と fieldname の名前です。 format-spec ::= ( fspec-item {, fspec-item } )この書式指定は、括弧に囲まれた複数の書式指定アイテムのリストで構成されます。詳細については、「書式指定アイテム」を参照してください。 情報メモfrom_field は、テーブルの項目を区切るときのリスト区切り記号として、カンマのみをサポートします。 |
| inline | スクリプト内でデータを入力し、ファイルからロードしない場合は、inline を使用します。 data ::= [ text ] inline 節を使用してい入力するデータは、二重引用符または角括弧で囲む必要があります。括弧で囲まれたテキストは、ファイルのコンテンツと同じ方法で解釈されます。そのため、テキスト ファイルで新しい行を挿入する場合と同様に、inline 節のテキストについても Enter キーを押します。列の数は最初の行で定義されています。 format-spec ::= ( fspec-item {, fspec-item } )この書式指定は、括弧に囲まれた複数の書式指定アイテムのリストで構成されます。詳細については、「書式指定アイテム」を参照してください。 |
| resident | 事前にロード済みのテーブルからデータをロードする場合は、resident を使用します。 table label は、元のテーブルを作成した LOAD または SELECT ステートメントの前に配置されるラベルです。ラベルの最後にはコロン (:) を記述します。 |
| autogenerate | Qlik Sense でデータを自動生成する場合は、autogenerate を使用します。 size ::= number Number は、生成するレコード数を示す整数です。 Peek 関数を使用して、以前にロードされたテーブルの 1 つの項目値を参照しない限り、項目のリストには、外部データ ソースまたは以前にロードされたテーブルからデータを取得する必要のある数式を記述できません。 |
| extension | 分析接続からデータをロードすることができます。サーバーサイド拡張 (SSE) プラグインで定義されている関数を呼び出す、またはスクリプトを評価する extension 節を使用する必要があります。 SSE プラグインに単一のテーブルを送ることができます。単一のデータ テーブルが返されます。返す項目名が SSE プラグインで指定されていない場合、項目には Field1, Field2 などの名前が付けられます。 Extension pluginname.functionname( tabledescription );
テーブル項目定義におけるデータ型の扱い データ型は、分析接続で自動的に検出されます。データに数値が含まれず、少なくとも 1 個の非 NULL テキスト文字列が含まれる場合、その項目はテキストとみなされます。それ以外の場合は数値とみなされます。 String() または Mixed() で項目名を囲むことで、データ型を強制的に指定できます。
拡張テーブル項目定義以外では、String()、Mixed() は使用できず、テーブル項目定義では他の Qlik Sense 関数を使用できません。 分析接続に関する詳細 分析接続は、使用する前に設定が必要です。 Qlik Sense Enterprise:分析接続の作成 Qlik Sense Desktop: における分析接続の構成Qlik Sense Desktop GitHub リポジトリでは分析接続に関する詳細を閲覧できます。qlik-oss/server-side-extension |
| where | where 節は、レコードを選択に含めるかどうかを示します。criterion が True の場合は選択が含まれます。 criterion は論理式です。 |
| while | while は、レコードを繰り返し読み取るかどうかを示す節です。criterion が True の場合は、同じレコードが読み取られます。通常、while 節には IterNo( ) 関数が含まれていなければなりません。 criterion は論理式です。 |
| group by | データを集計 (グループ化) すべき項目を定義するには、group by 節を使用します。 集計項目は、ロードする数式に挿入しなければなりません。集計項目以外の項目は、ロードした数式に含まれる集計関数の外部で使用できます。 groupbyfieldlist ::= (fieldname { ,fieldname } ) |
| order by | order by 節は、load ステートメントで処理される前に、常駐テーブルのレコードをソートします。1 つ以上の項目の昇順または降順で、常駐テーブルをソートできます。最初に数値、次に各国の照合順でソートされます。この節は、データ ソースが常駐テーブルの場合に限り使用できます。 順序項目は、常駐テーブルをソートする項目を指定します。項目は、名前または常駐テーブル内での番号 (最初の項目が番号 1) で指定できます。 orderbyfieldlist ::= fieldname [ sortorder ] { , fieldname [ sortorder ] } sortorder は、昇順の asc または降順の desc のどちらかになります。sortorder を指定しない場合は、asc と見なされます。 fieldname、path、filename、aliasname は、それぞれの名前を示すテキスト文字列です。ソース テーブルのフィールドは fieldname として使用できます。ただし、as 節 (aliasname) を使用して作成された項目は範囲外になり、同じ load ステートメント内では使用できません。 |
from、inline、resident、from_field、extension、または autogenerate 節でデータのソースが指定されない場合、データは直後の SELECT または LOAD ステートメントの結果からロードされます。後続のステートメントには、プレフィックスを記述できません。
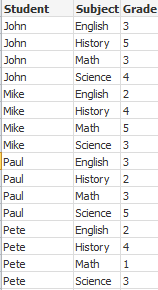
この例では、ひとつの項目に各生徒の成績が要約して含まれている、入力ファイル Grades.csv があります。
Student,Grades
Mike,5234
John,3345
Pete,1234
Paul,3352
成績は、1 から 5 に分かれていて、科目 Math、English、Science、および History を表しています。IterNo( ) 関数をカウンタとして使用して、各レコードを複数回、while 句で読み取り、成績を個々の値に分けることができます。読み取るたびに、Mid 関数で成績が抽出され、Grade に保存され、科目が pick 関数を使用して選択され、Subject に保存されます。最後の while 節には、全成績が読み取られたか確認するテスト (この場合、生徒 1 人に付き 4 教科分) が含まれています。その後、次の生徒の成績を読み取ります。
MyTab:
LOAD Student,
mid(Grades,IterNo( ),1) as Grade,
pick(IterNo( ), 'Math', 'English', 'Science', 'History') as Subject from Grades.csv
while IsNum(mid(Grades,IterNo(),1));
結果は、このデータが含まれるテーブルにあります。