
Rank() berechnet die Zeilen des Diagramms in der Formel und zeigt für jede Zeile die relative Position des Wertes der Dimension an, die in der Formel berechnet wird. Beim Auswerten der Formel vergleicht die Funktion ihr Ergebnis mit den Ergebnissen für andere Zeilen innerhalb des Spaltenabschnitts und liefert den Rang der Zeile innerhalb des Spaltenabschnitts.
Spaltensegmente
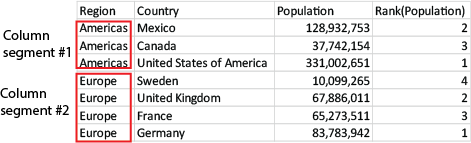
Bei anderen Diagrammen als Tabellen wird der aktuelle Spaltenabschnitt so definiert, wie er im entsprechenden Tabellendiagramm des Diagramms erscheint.
Syntax:
Rank([TOTAL] expr[, mode[, fmt]])
Rückgabe Datentyp: dual
Argumente:
| Argument | Beschreibung |
|---|---|
| expr | Die Formel oder das Feld mit den Daten, die gemessen werden sollen. |
| mode | Definiert die numerische Repräsentation des Rangs. |
| fmt | Definiert die Textrepräsentation des Rangs. |
| TOTAL |
Wenn das Diagramm nur eine Dimension hat oder die Formel mit dem Qualifizierer TOTAL versehen ist, wird die Funktion über die gesamten Spalte ausgewertet. Hat das Diagramm mehrere vertikale Dimensionen, so umfasst der aktuelle Spaltenabschnitt nur Zeilen mit denselben Werten wie in der aktuellen Zeile in allen Dimensionsspalten, mit Ausnahme der in der Priorität der Sortierfolgen letzten Dimension. |
Der Rang ist eine duale Größe. Hat jede Spalte einen eindeutigen Rang, wird dieser als ganze Zahl zwischen 1 und der Zahl der Zeilen des aktuellen Zeilenabschnitts ausgegeben.
Teilen sich mehrere Zeilen denselben Rang, kann das Ergebnis der Funktion durch die Parameter mode und fmt modifiziert werden.
mode
Das zweite Argument mode kann folgende Werte annehmen:
| Wert | Beschreibung |
|---|---|
| 0 (Standard) |
Fallen die Ränge alle unterhalb des mittleren Ranges der gesamten Rangfolge, erhalten alle Zeilen der Gruppe den geringsten innerhalb dieser Gruppe auftretenden Rang. Fallen die Ränge alle oberhalb des mittleren Ranges der gesamten Rangfolge, erhalten alle Zeilen der Gruppe den höchsten innerhalb dieser Gruppe auftretenden Rang. Geht die Gruppe der Zeilen gleichen Rangs über den mittleren Rang der gesamten Rangfolge hinweg, erhalten alle Zeilen der Gruppe den mittleren Rang der gesamten Rangfolge. |
| 1 | Alle Zeilen erhalten den niedrigsten Rang. |
| 2 | Alle Zeilen erhalten den mittleren Rang. |
| 3 | Alle Zeilen erhalten den höchsten Rang. |
| 4 | Die erste Zeile erhält den niedrigsten Rang, für die Ränge nachfolgender Zeilen wird jeweils eins addiert. |
fmt
Das dritte Argument fmt kann folgende Werte annehmen:
| Wert | Beschreibung |
|---|---|
| 0 (Standard) | Niedrigster Wert - höchster Wert in allen Zeilen (z. B. 3 - 4). |
| 1 | Niedrigster Wert in allen Zeilen. |
| 2 | Niedrigster Wert in der ersten Zeile, leere Zeilen in allen weiteren Zeilen. |
Die für mode 4 und fmt 2 maßgebliche Reihenfolge ist die Sortierfolge der Diagrammdimension.
Beispiele und Ergebnisse:
Erstellen Sie zwei Visualisierungen aus den Dimensionen Product und Sales und eine weitere aus Product und UnitSales. Fügen Sie, wie in der folgenden Tabelle gezeigt, Kennzahlen hinzu.
| Beispiele | Ergebnisse |
|---|---|
|
Beispiel 1. Erstellen Sie eine Tabelle mit den Dimensionen Customer und Sales und der Kennzahl Rank(Sales). |
Das Ergebnis hängt von der Sortierreihenfolge der Dimensionen ab. Wenn die Tabelle nach Customer sortiert wird, werden in der Tabelle alle Werte für Sales fürAstrida, danach fürBetacab usw. aufgeführt. Die Ergebnisse für Rank(Sales) zeigen 10 für den Wert Sales 12, 9 für den Wert Sales 13 usw. an, wobei sich der Rangwert 1 für den Wert Sales 78 ergibt. Der nächste Spaltenabschnitt beginnt mit Betacab, für den der erste Wert von Sales im Segment 12 ist. Für den Rangwert von Rank(Sales) ergibt sich 11. Wird die Tabelle nach Sales sortiert, bestehen die Spaltenabschnitte aus den Werten von Sales und dem entsprechenden Customer. Weil es zwei Werte Sales 12 gibt (für Astrida und Betacab), ergibt sich für den Wert von Rank(Sales) für jeden Wert von Customer dieses Spaltenabschnitts 1-2. Grund hierfür ist, dass es zwei Werte Customer gibt, bei denen der Wert Sales 12 beträgt. Im Fall von 4 Werten wäre das Ergebnis für alle Zeilen 1-4. Hier wird gezeigt, wie das Ergebnis für den Standardwert (0) des Arguments fmt aussieht. |
| Beispiel 2. Ersetzen Sie die Dimension „Kunde“ durch „Produkt“ und fügen Sie die Kennzahl Rank(Sales,1,2) hinzu. | Dadurch ergibt sich für die erste Zeile jedes Spaltenabschnitts 1 und alle anderen Zeilen bleiben leer, da für die Argumente mode und fmt 1 bzw. 2 gewählt wurde. |
Ergebnis aus Beispiel 1, Tabelle sortiert nach Customer:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 10 |
| Astrida | 13 | 9 |
| Astrida | 20 | 8 |
| Astrida | 22 | 7 |
| Astrida | 45 | 6 |
| Astrida | 46 | 5 |
| Astrida | 60 | 4 |
| Astrida | 65 | 3 |
| Astrida | 70 | 2 |
| Astrida | 78 | 1 |
| Betcab | 12 | 11 |
Ergebnis aus Beispiel 1, Tabelle sortiert nach Sales:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 1-2 |
| Betacab | 12 | 1-2 |
| Astrida | 13 | 1 |
| Betacab | 15 | 1 |
| Astrida | 20 | 1 |
| Astrida | 22 | 1-2 |
| Betacab | 22 | 1-2 |
| Betacab | 24 | 1-2 |
| Canutility | 24 | 1-2 |
In Beispielen verwendete Daten:
ProductData:
Load * inline [
Customer|Product|UnitSales|UnitPrice
Astrida|AA|4|16
Astrida|AA|10|15
Astrida|BB|9|9
Betacab|BB|5|10
Betacab|CC|2|20
Betacab|DD|0|25
Canutility|AA|8|15
Canutility|CC|0|19
] (delimiter is '|');
Sales2013:
crosstable (Month, Sales) LOAD * inline [
Customer|Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec
Astrida|46|60|70|13|78|20|45|65|78|12|78|22
Betacab|65|56|22|79|12|56|45|24|32|78|55|15
Canutility|77|68|34|91|24|68|57|36|44|90|67|27
Divadip|57|36|44|90|67|27|57|68|47|90|80|94
] (delimiter is '|');