
Rank - chart function
Rank() evaluates the rows of the chart in the expression, and for each row, displays the relative position of the value of the dimension evaluated in the expression. When evaluating the expression, the function compares the result with the result of the other rows containing the current column segment and returns the ranking of the current row within the segment.
Column segments
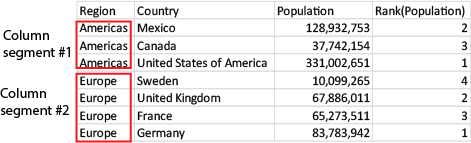
For charts other than tables, the current column segment is defined as it appears in the charts straight table equivalent.
Syntax:
Rank([TOTAL] expr[, mode[, fmt]])
Return data type: dual
Arguments:
| Argument | Description |
|---|---|
| expr | The expression or field containing the data to be measured. |
| mode | Specifies the number representation of the function result. |
| fmt | Specifies the text representation of the function result. |
| TOTAL |
If the chart is one-dimensional, or if the expression is preceded by the TOTAL qualifier, the function is evaluated along the entire column. If the table or table equivalent has multiple vertical dimensions, the current column segment will include only rows with the same values as the current row in all dimension columns except for the column showing the last dimension in the inter-field sort order. |
The ranking is returned as a dual value, which in the case when each row has a unique ranking, is an integer between 1 and the number of rows in the current column segment.
In the case where several rows share the same ranking, the text and number representation can be controlled with the mode and fmt parameters.
mode
The second argument, mode, can take the following values:
| Value | Description |
|---|---|
| 0 (default) |
If all ranks within the sharing group fall on the low side of the middle value of the entire ranking, all rows get the lowest rank within the sharing group. If all ranks within the sharing group fall on the high side of the middle value of the entire ranking, all rows get the highest rank within the sharing group. If ranks within the sharing group span over the middle value of the entire ranking, all rows get the value corresponding to the average of the top and bottom ranking in the entire column segment. |
| 1 | Lowest rank on all rows. |
| 2 | Average rank on all rows. |
| 3 | Highest rank on all rows. |
| 4 | Lowest rank on first row, then incremented by one for each row. |
fmt
The third argument, fmt, can take the following values:
| Value | Description |
|---|---|
| 0 (default) | Low value - high value on all rows (for example 3 - 4). |
| 1 | Low value on all rows. |
| 2 | Low value on first row, blank on the following rows. |
The order of rows for mode 4 and fmt 2 is determined by the sort order of the chart dimensions.
Examples and results:
Create two visualizations from the dimensions Product and Sales and another from Product and UnitSales. Add measures as shown in the following table.
| Examples | Results |
|---|---|
|
Example 1. Create a table with the dimensions Customer and Sales and the measure Rank(Sales) |
The result depends on the sort order of the dimensions. If the table is sorted on Customer, the table lists all the values of Sales for Astrida, then Betacab, and so on. The results for Rank(Sales) will show 10 for the Sales value 12, 9 for the Sales value 13, and so on, with the rank value of 1 returned for the Sales value 78. The next column segment begins with Betacab, for which the first value of Sales in the segment is 12. The rank value of Rank(Sales) for this is given as 11. If the table is sorted on Sales, the column segments consist of the values of Sales and the corresponding Customer. Because there are two Sales values of 12 (for Astrida and Betacab), the value of Rank(Sales) for that column segment is 1-2, for each value of Customer. This is because there are two values of Customer for the Sales value 12. If there had been 4 values, the result would be 1-4, for all rows. This shows what the result looks like for the default value (0) of the argument fmt. |
| Example 2. Replace the dimension Customer with Product and add the measure Rank(Sales,1,2) | This returns 1 on the first row on each column segment and leaves all other rows blank, because arguments mode and fmt are set to 1 and 2 respectively. |
Results for example 1, with table sorted on Customer:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 10 |
| Astrida | 13 | 9 |
| Astrida | 20 | 8 |
| Astrida | 22 | 7 |
| Astrida | 45 | 6 |
| Astrida | 46 | 5 |
| Astrida | 60 | 4 |
| Astrida | 65 | 3 |
| Astrida | 70 | 2 |
| Astrida | 78 | 1 |
| Betcab | 12 | 11 |
Results for example 1, with table sorted on Sales:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 1-2 |
| Betacab | 12 | 1-2 |
| Astrida | 13 | 1 |
| Betacab | 15 | 1 |
| Astrida | 20 | 1 |
| Astrida | 22 | 1-2 |
| Betacab | 22 | 1-2 |
| Betacab | 24 | 1-2 |
| Canutility | 24 | 1-2 |
Data used in examples:
ProductData:
Load * inline [
Customer|Product|UnitSales|UnitPrice
Astrida|AA|4|16
Astrida|AA|10|15
Astrida|BB|9|9
Betacab|BB|5|10
Betacab|CC|2|20
Betacab|DD|0|25
Canutility|AA|8|15
Canutility|CC|0|19
] (delimiter is '|');
Sales2013:
crosstable (Month, Sales) LOAD * inline [
Customer|Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec
Astrida|46|60|70|13|78|20|45|65|78|12|78|22
Betacab|65|56|22|79|12|56|45|24|32|78|55|15
Canutility|77|68|34|91|24|68|57|36|44|90|67|27
Divadip|57|36|44|90|67|27|57|68|47|90|80|94
] (delimiter is '|');