
入力フローの設定
手順
-
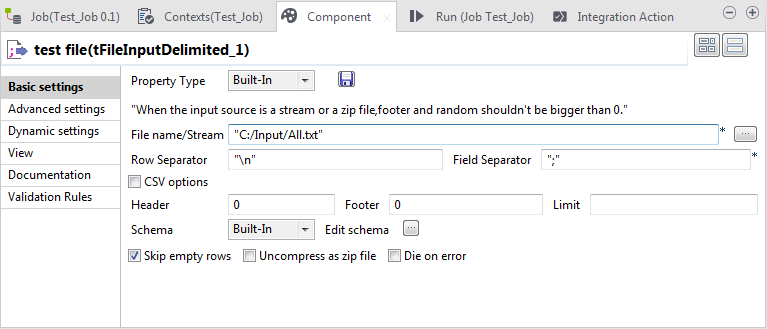
tFileInputDelimitedをダブルクリックして、[Component] (コンポーネント)ビューを開きます。
-
 ボタンをクリックしてスキーマエディターを開き、ここで顧客データストラクチャーを反映するスキーマを作成する必要があります。
ボタンをクリックしてスキーマエディターを開き、ここで顧客データストラクチャーを反映するスキーマを作成する必要があります。
-
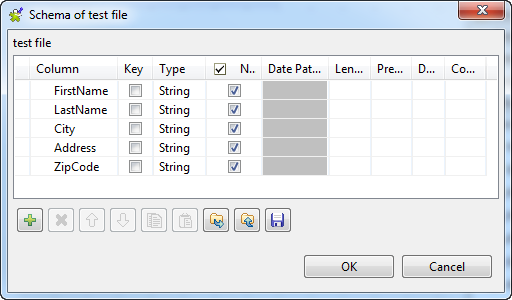
 ボタンを5回クリックして5つの行を追加し、次のように名前を変更します: FirstName、LastName、City、Address、ZipCode。
このシナリオでは、データ型は、デフォルト値の[String] (文字列)のままにしておきます。実際の業務では、処理するデータのデータ型に合わせて変更します。
ボタンを5回クリックして5つの行を追加し、次のように名前を変更します: FirstName、LastName、City、Address、ZipCode。
このシナリオでは、データ型は、デフォルト値の[String] (文字列)のままにしておきます。実際の業務では、処理するデータのデータ型に合わせて変更します。