
Importing data to the Neo4j database
Procedure
-
Double-click the tFileInputDelimited
component to open its Basic settings view
on the Components tab.
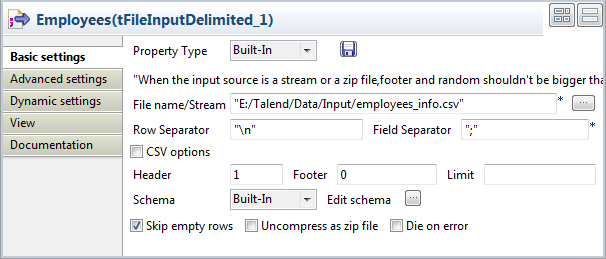
-
Click the [...] button next to Edit schema to open the Schema dialog box, and define the input schema based on
the structure of the input file. In this example, the input schema is
composed of six columns: employeeID
(integer), employeeName (String),
age (Integer), hireDate (Date), salary (Float), and managerID (String).
When done, click OK to close the Schema dialog box and propagate the schema to the next component.

-
Click the tNeo4jOutput component and
select the Component tab to open its
Basic settings view.
