
Top() interpretiert eine Formel in der ersten (obersten) Zeile eines Spaltenabschnitts in einer Tabelle. Die Zeile, für welche die Berechnung erfolgt, hängt vom Wert von offset ab; ist dieser vorhanden, wird standardmäßig die oberste Zeile verwendet. In Diagrammen erfolgt anders als in Tabellen mit Top() die Berechnung für die erste Zeile der aktuellen Spalte im entsprechenden Tabellendiagramm.
Syntax:
Top([TOTAL] expr [ , offset [,count ]])
Rückgabe Datentyp: dual
Argumente:
| Argument | Beschreibung |
|---|---|
| expr | Die Formel oder das Feld mit den Daten, die gemessen werden sollen. |
| offset |
Ist ein offset von n größer als 1 angegeben, wird die Formel anhand der Werte von n Zeilen berechnet, die unterhalb der obersten Zeile liegen. Bei einem negativen Startwert verhält sich die Funktion Top wie die Funktion Bottom mit dem entsprechenden positiven Startwert. |
| count | Ist ein dritter Parameter count größer als 1 angegeben, liefert die Funktion eine Menge von count-Werten, berechnet anhand der letzten count-Zeilen des Spaltenabschnitts. In diesem Formular kann die Funktion als Argument für eine der speziellen Abschnittsfunktionen dienen. Bereichsfunktionen |
| TOTAL |
Wenn das Diagramm nur eine Dimension hat oder die Formel mit dem Zusatz TOTAL als Argument versehen ist, entspricht der Spaltenabschnitt der gesamten Spalte. |
Beschränkungen:
-
Die Rekursion liefert NULL.
-
Das Sortieren nach y-Werten in Diagrammen oder nach Formelspalten in Tabellen ist nicht zulässig, wenn diese Diagrammfunktion in einer der Diagrammformeln verwendet wird. Diese Sortierungsoptionen werden daher automatisch deaktiviert. Wenn Sie diese Diagrammfunktion in einer Visualisierung oder Tabelle verwenden, wird die Sortierung der Visualisierung auf die sortierte Eingabe dieser Funktion zurückgesetzt.
Beispiele und Ergebnisse:
Beispiel: 1
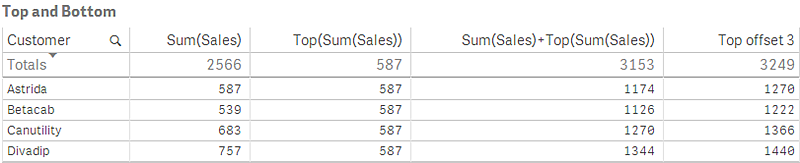
Im Screenshot der in diesem Beispiel gezeigten Tabelle wird die Tabellenvisualisierung aus der Dimension Customer und den Kennzahlen Sum(Sales) und Top(Sum(Sales)) erstellt.
Die Spalte Top(Sum(Sales)) gibt 587 für alle Zeilen zurück, weil dies der Wert für die oberste Zeile ist: Astrida.
In der Tabelle werden auch komplexere Kennzahlen angezeigt: eine aus Sum(Sales)+Top(Sum(Sales)) erstellte und eine mit Top offset 3 beschriftete Kennzahl, die mithilfe der Formel Sum(Sales)+Top(Sum(Sales), 3) erstellt wird und über das Argument offset mit der Einstellung 3 verfügt. Sie fügt den Wert Sum(Sales) für die aktuelle Zeile zum Wert aus der dritten Zeile unter der obersten Zeile hinzu, d. h. die aktuelle Zeile plus den Wert für Canutility.
Beispiel: 2
In den Screenshots der in diesem Beispiel gezeigten Tabellen wurden den Visualisierungen weitere Dimensionen hinzugefügt: Month und Product. Bei Diagrammen mit mehr als einer Dimension hängt das Ergebnis der Formeln, welche die Funktionen Above, Below, Top und Bottom beinhalten, von der Reihenfolge ab, in der die Spaltendimensionen von Qlik Sense sortiert werden. Qlik Sense evaluiert die Funktionen auf Grundlage der Spaltenabschnitte, die sich aus der zuletzt sortierten Dimension ergeben haben. Die Sortierreihenfolge der Spalten kann im Eigenschaftsfenster unter Sortierung festgelegt werden und stimmt nicht zwangsläufig mit der Reihenfolge überein, in der die Spalten in der Tabelle angezeigt werden.
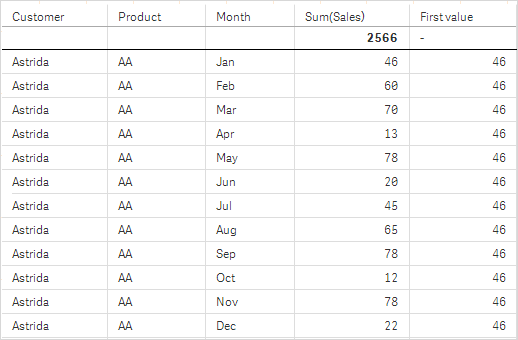
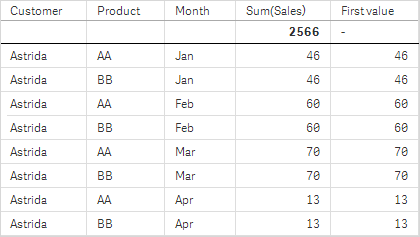
Siehe Beispiel: 2 in der Funktion Above für weitere Details.
|
Beispiel: 3 |
Ergebnis | ||
|---|---|---|---|
|
Die Funktion Top kann als Input für die Abschnittsfunktionen verwendet werden. Hier ein Beispiel: RangeAvg (Top(Sum(Sales),1,3)). |
In den Argumenten für die Funktion Top() wird offset auf 1 und auf count gesetzt. Die Funktion ermittelt die Ergebnisse der Formel Sum(Sales) zu den drei Zeilen, beginnend bei der Zeile unterhalb der untersten Zeile im Spaltenabschnitt (weil offset=1), und den zwei Zeilen darunter (sofern Zeilen vorhanden sind). Diese drei Werte werden als Input für die Funktion RangeAvg() verwendet, die den Durchschnitt der Werte in der gelieferten Menge an Zahlen ermittelt. Eine Tabelle mit Customer als Dimension liefert folgende Ergebnisse für die Formel RangeAvg(). |
||
|