From the tMatchGroup configuration wizard, you can import match keys from the
match rules created and tested in the
Profiling
perspective. You can then use these imported matching keys in your match
Jobs.
The tMatchGroup component enables you
to import from the Talend Studio
repository match rules based on the VSR or the T-Swoosh algorithms.
The VSR algorithm takes a set of records as input and groups similar encountered
duplicates together according to defined match rules. It compares pairs of records and
assigns them to groups. The first processed record of each group is the master record of the
group. The VSR algorithm compares each record with the master of each group and uses the
computed distances, from master records, to decide to what group the record should go.
The T-Swoosh algorithm enables you to find duplicates and to define how
two similar records are merged to create a master record, using a survivorship function.
These new merged records are used to find new duplicates. The difference with the VSR
algorithm is that the master record is in general a new record that does not exist in
the list of input records.
-
From the configuration wizard, click the
 icon on the top right corner.
icon on the top right corner.
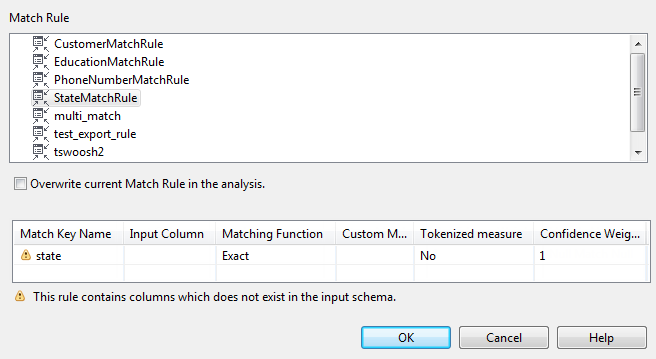
The Match Rule Selector
wizard opens listing all match rules created in Talend Studio and saved in the repository.
-
Select the match rule you want to import into the tMatchGroup component and use on your data.
A warning message displays in the wizard if the match rule you want to import is
defined on columns that do not exist in the input schema of tMatchGroup. You can define input columns later in the configuration
wizard.
It is important to have the same type of the matching algorithm
selected in the basic settings of the component and imported from the
configuration wizard. Otherwise the Job runs with default values for the
parameters which are not compatible between the two algorithms.
Information noteRemember: If you are using the Apache Spark Batch component, do not
import a match rule using the T-Swoosh algorithm. The component does not
support this algorithm.
-
Select the Overwrite current Match Rule in the
analysis check box if you want to replace the rule in the
configuration wizard with the rule you import.
If you leave the box unselected, the match keys will be imported in a new match
rule tab without overwriting the current match rule in the wizard.
-
Click OK.
The matching key is imported from the match rule and listed as a new rule in the
configuration wizard.
-
Click in the Input Key Attribute and select from
the input data the column on which you want to apply the matching key.
-
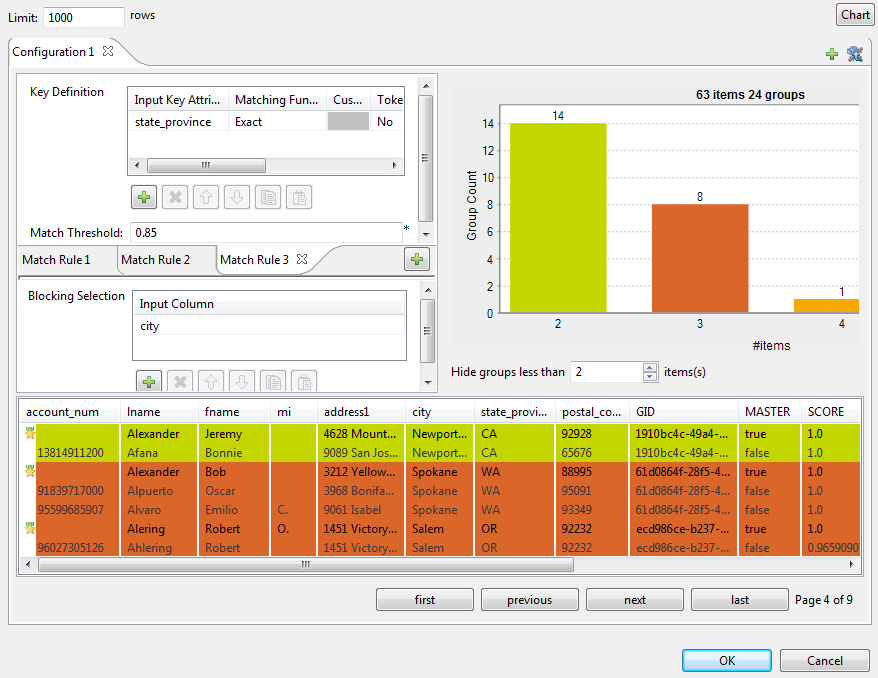
In the Match threshold
field, enter the match probability threshold.
Two data records match when the computed match score is greater than or equal
to this value.
-
In the Blocking
Selection table, select the columns from the input flow which
you want to use as a blocking key.
Defining a blocking key is not mandatory but advisable. Using
a blocking key partitions data in blocks and so reduces the number of records
that need to be examined, as comparisons are restricted to record pairs in each
block. Using blocking keys is very useful when you are processing big
datasets.
The Blocking Selection
table in the component is different from the Generation of Blocking Key table in the match rule editor of
the
Profiling
perspective.
The blocking column in tMatchGroup can come from a tGenKey component, and would be called T_GEN_KEY, or directly from the input schema, it can be a ZIP column for instance. While the Generation of Blocking Key table in the match
rule editor defines the parameters necessary to generate a blocking key; this
table is equivalent to the tGenKey
component. The Generation of Blocking Key
table generates a blocking column BLOCK_KEY used for
blocking.
-
Click the Chart button in the top right corner of
the wizard to execute the Job using the imported match rule and show the matching
results in the wizard.