
Evaluating the classification model
After you created a classification model, you can evaluate how good it
is.
Linking the components
Procedure
-
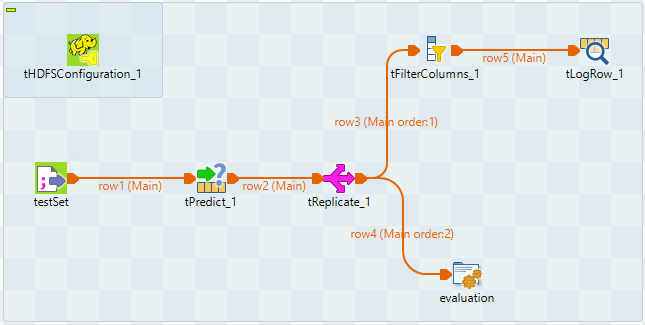
Except tHDFSConfiguration, connect them
using the Row > Main link as is displayed
in the image above.
Loading the test set into the Job
Procedure
-
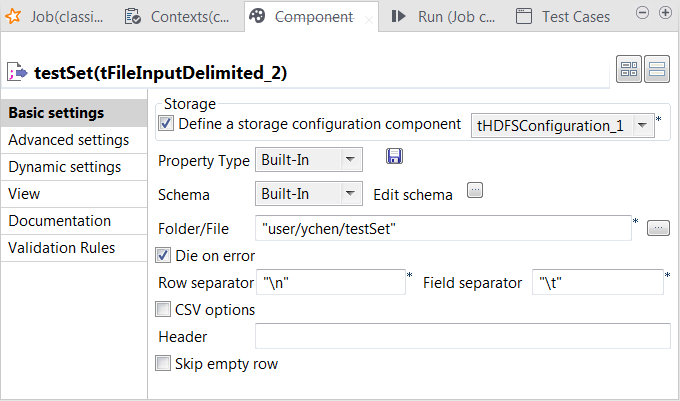
Double-click tFileInputDelimited to open its
Component view.
-
Click the [+] button five times to add five rows and in the
Column column, rename them to reallabel, sms_contents, num_currency,
num_numeric and num_exclamation, respectively.
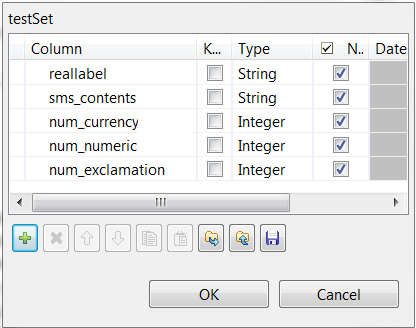 The reallabel and the sms_contents columns carries the raw data which is composed of the SMS text messages in the sms_contents column and the labels indicating whether a message is spam in the reallabel column.The other columns are used to carry the features added to the raw datasets as explained previously in this scenario. They contains the number of currency symbols, the number of numeric values and the number of exclamation marks found in each SMS message.
The reallabel and the sms_contents columns carries the raw data which is composed of the SMS text messages in the sms_contents column and the labels indicating whether a message is spam in the reallabel column.The other columns are used to carry the features added to the raw datasets as explained previously in this scenario. They contains the number of currency symbols, the number of numeric values and the number of exclamation marks found in each SMS message.
Applying the classification model
Procedure
-
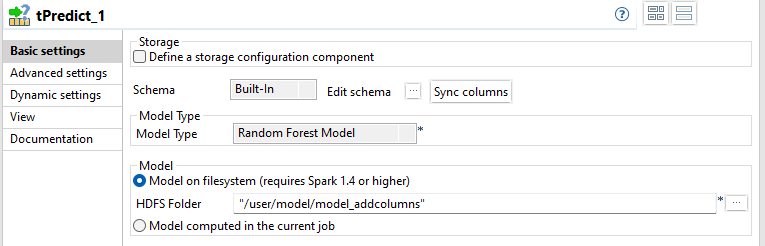
Double-click tPredict to
open its Basic settings.
-
Select the Model on filesystem radio button and enter the
directory in which the classification model to be used is stored.
The tPredict component contains a read-only column called label in which the model provides the classes to be used in the classification process, while the reallabel column retrieved from the input schema contains the classes to which each message actually belongs. The model will be evaluated by comparing the actual label of each message with the label the model determines.
Replicating the classification result
Procedure
-
Double-click tReplicate to open its
Component view.
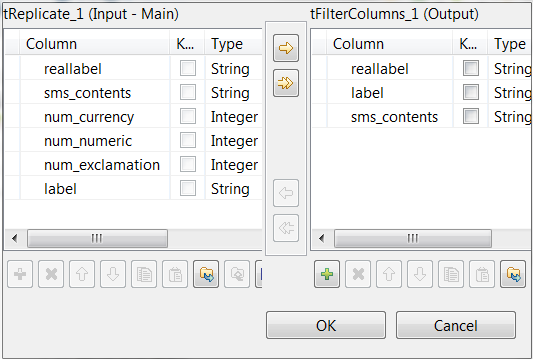
Filtering the classification result
Procedure
-
On the output side, click the [+] button three times to add
three rows and in the Column column, rename
them to reallabel, label and sms_contents, respectively. They receive data from the input
columns that are using the same names.
Writing the evaluation program in tJava
Procedure
-
Click the Advanced settings tab to open its view.
Configuring Spark connection
About this task
Repeat the operations described above. See Selecting the Spark mode.
Executing the Job
Procedure
Results
In the console of the Run view, you can read the classification result along with the actual labels:
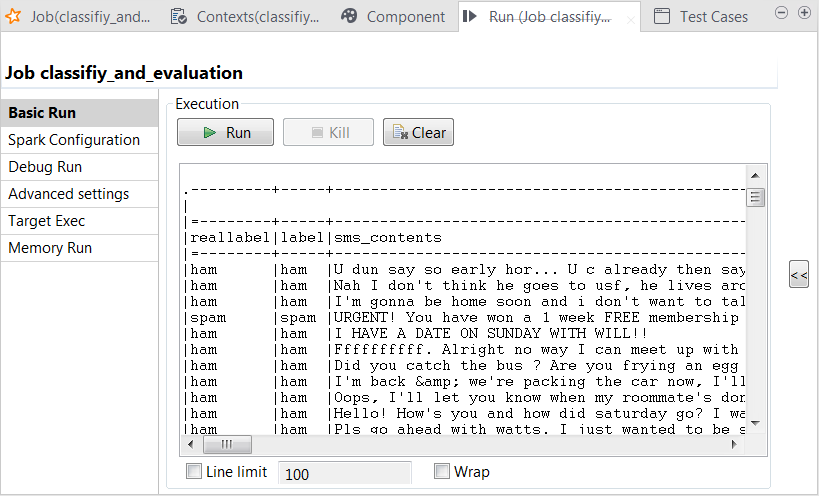
You can also read the computed scores in the same console:
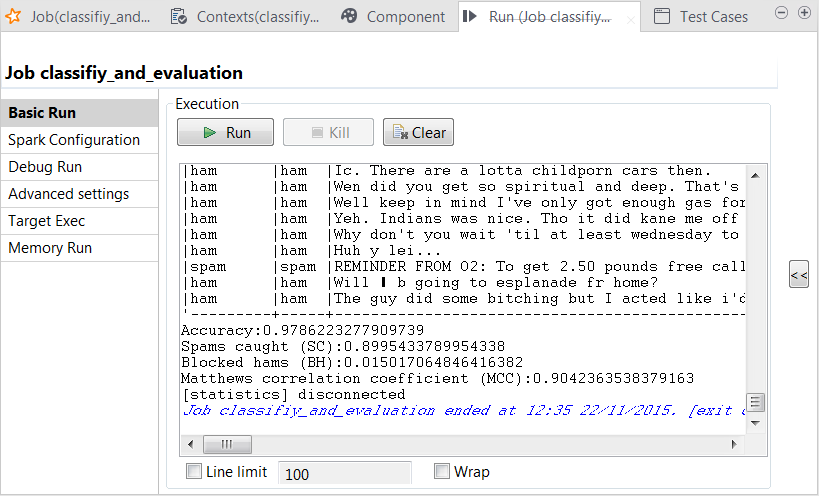
The scores show a good quality of the model. You can still enhance the model by continuing to tune the parameters used in tRandomForestModel and run the model-creation Job with new parameters to obtain and then evaluate new versions of the model.