
Talend Big Dataのファンクションアーキテクチャー
Talend Big Dataソリューションのファンクションアーキテクチャーとは、Talendビッグデータソリューションのファンクション、インタラクション、対応するITのニーズを特定するアーキテクチャーモデルを指します。
アーキテクチャー全体はこれまで、特定の機能を機能ブロックに分離することで説明されてきました。
Talend Studioでのビッグデータ処理に関連するアーキテクチャー上の主な機能ブロックは次のとおりです。
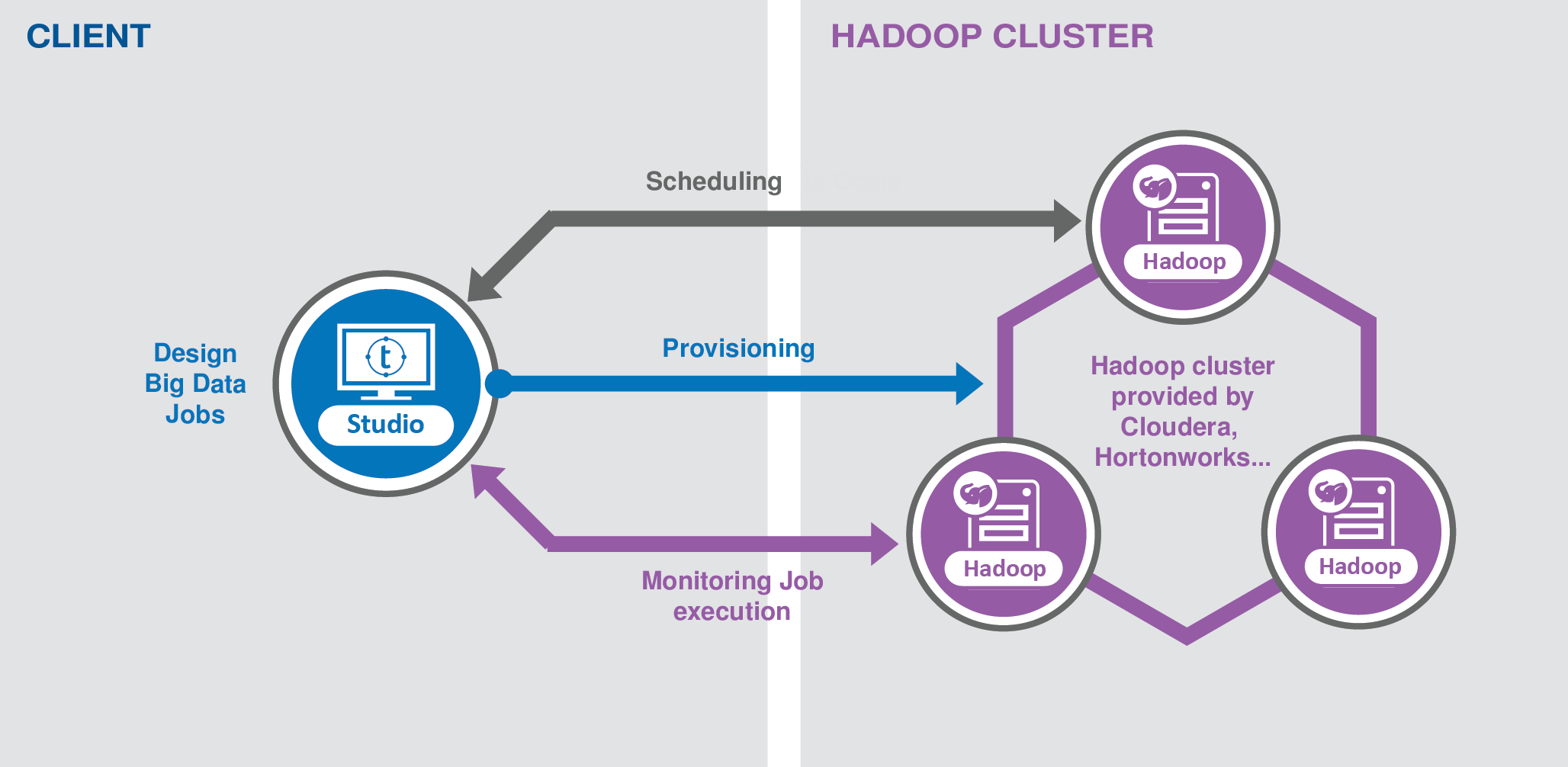
3つの異なるタイプの機能ブロックが定義されています。
-
少なくとも1つのTalend Studioインスタンス: Apache Hadoopプラットフォームを活用して、大量のデータセットを処理するビッグデータジョブをデザインします。これらのジョブはローカルで実行することもできますが、Hadoopグリッド上にデプロイ、スケジューリング、実行することもできます。
-
サブスクリプションベースのワークフローのスケジューラーシステムを通じて、Hadoopグリッド上にビッグデータジョブをデプロイ、スケジューリング、実行し、ジョブの実行ステータスや結果を監視できます。
-
Talendシステムから独立したHadoopグリッドでは、大量のデータセットを処理します。