個別値の抽出
始める前に
このタスクについて
これで、その他のデータ標準化プロセスの参照データセットとしてこの個別値を使用できるようになります。
以下の例では、MySQLデータベースでのpostal_codeカラムの分析がProfilingパースペクティブで作成および実行されています。
手順
-
分析エディターで、[Value Frequency] (値の頻度)インジケーターを右クリックします。
![[分析済みカラム]セクションからのインジケーターのコンテキストメニュー。](/talend/ja-JP/studio-user-guide/8.0-R2024-10/Content/Resources/images/job_extract_distinct_values.png)
-
[Generate Job] (ジョブを生成)を選択します。
生成されたジョブでIntegrationパースペクティブが開きます。
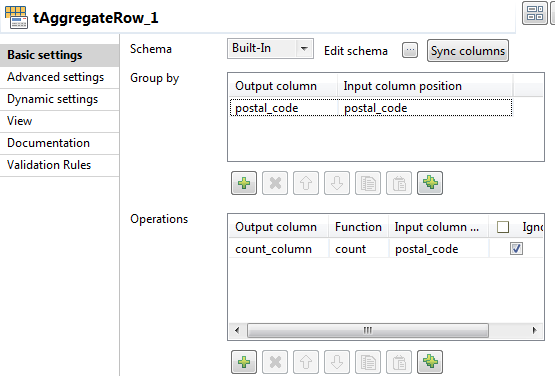
 データベースコンポーネントの基本設定は、カラム分析で使用したデータベース接続に従って定義済みです。tAggregateRowコンポーネントの基本設定は、postal_codeカラムの値の頻度から個別数をカウントするように定義済みです。
データベースコンポーネントの基本設定は、カラム分析で使用したデータベース接続に従って定義済みです。tAggregateRowコンポーネントの基本設定は、postal_codeカラムの値の頻度から個別数をカウントするように定義済みです。