
Reading full rows in a delimited file
Procedure
-
Link the tFileInputFullRow component to the
tLogRow component using a Row > Main connection.
-
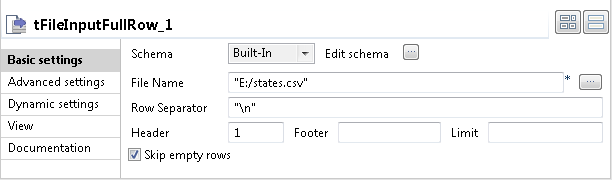
Double-click the tFileInputFullRow component to
open its Basic settings view on the Component tab.
-
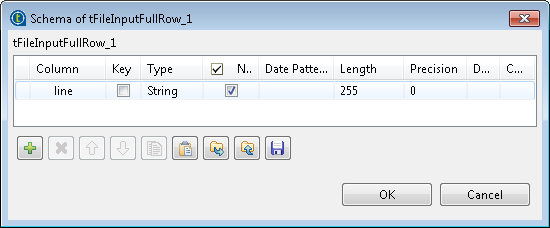
Click the [...] button next to Edit schema to view the data to be passed onto the
tLogRow component. Note that the schema is
read-only and it consists of only one column line.
-
Double-click the tLogRow component to open its
Basic settings view on the Component tab.
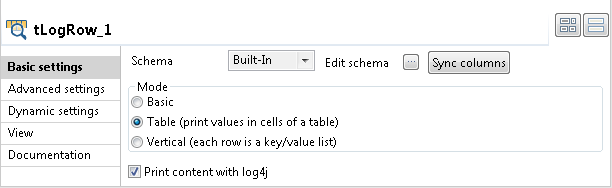 In the Mode area, select Table (print values in cells of a table) for better readability of the result.
In the Mode area, select Table (print values in cells of a table) for better readability of the result. -
Press Ctrl+S to save your Job and then F6 to execute it.
 As shown above, ten rows of data in the delimited file states.csv are read one by one, ignoring field separators, and the complete rows of data are displayed on the console.To extract fields from rows, you must use tExtractDelimitedFields, tExtractPositionalFields, or tExtractRegexFields. For more information, see tExtractDelimitedFields, tExtractPositionalFields and tExtractRegexFields.
As shown above, ten rows of data in the delimited file states.csv are read one by one, ignoring field separators, and the complete rows of data are displayed on the console.To extract fields from rows, you must use tExtractDelimitedFields, tExtractPositionalFields, or tExtractRegexFields. For more information, see tExtractDelimitedFields, tExtractPositionalFields and tExtractRegexFields.