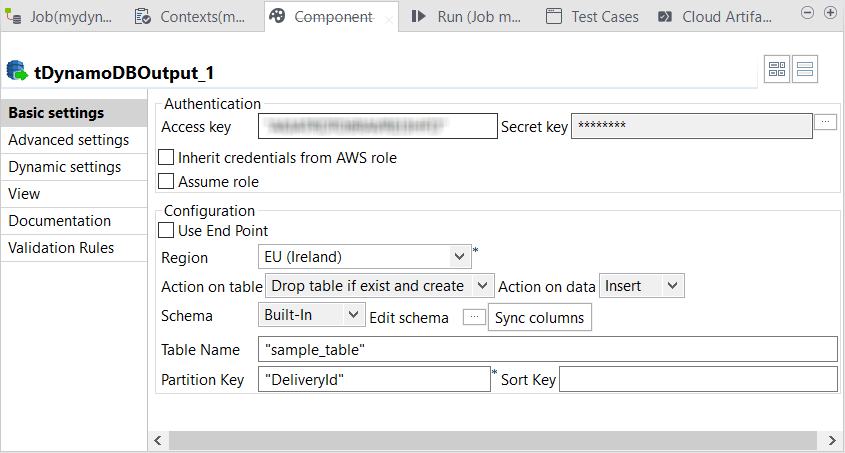
Writing the sample JSON documents to DynamoDB
Configure tFixedFlowInput to load the sample data in the data
flow and configure tdynamoDBOutput to write this data in a DynamoDB
table.
Procedure
-
Double-click tFixedFlowInput in its
Component view.
Example

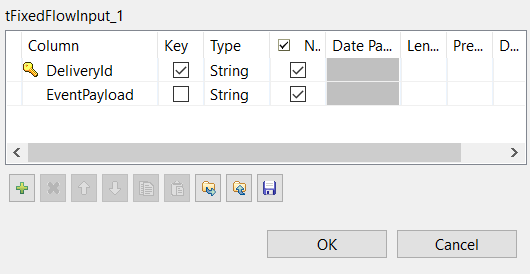
-
Click the ... button next to Edit
schema to open the schema editor.
Example
-
Double-click tdynamoDBOutput to open its
Component view.
Example