
Working with incremental data processing
This section shows you how process data incrementally using incremental blocks. Incremental blocks are a type of block that retrieves and updates records every time the automation is executed.
You can think of using incremental blocks like polling a data source. Incremental data processing is useful for processing historical data.
Overview of incremental blocks
Some data source connector blocks are incremental blocks. This means they process data incrementally, and they keep an internal pointer. You can tell if a block is an incremental block because the Pointers section is available on the block configuration pane only for incremental blocks.
You can modify these incremental block pointers with the pointer blocks.
Pointers are unique for for each combination of automation, automation type, block input, and the data source. This means that an incremental block with multiple inputs will have pointers for each input value, and two automations with the same incremental block will each have a unique pointer. If the same block is used twice in the same automation with the same inputs and same data source, then these two blocks will share the same pointer.
Each time the incremental block executes, it creates a pointer. Pointers are listed under the Pointers section.
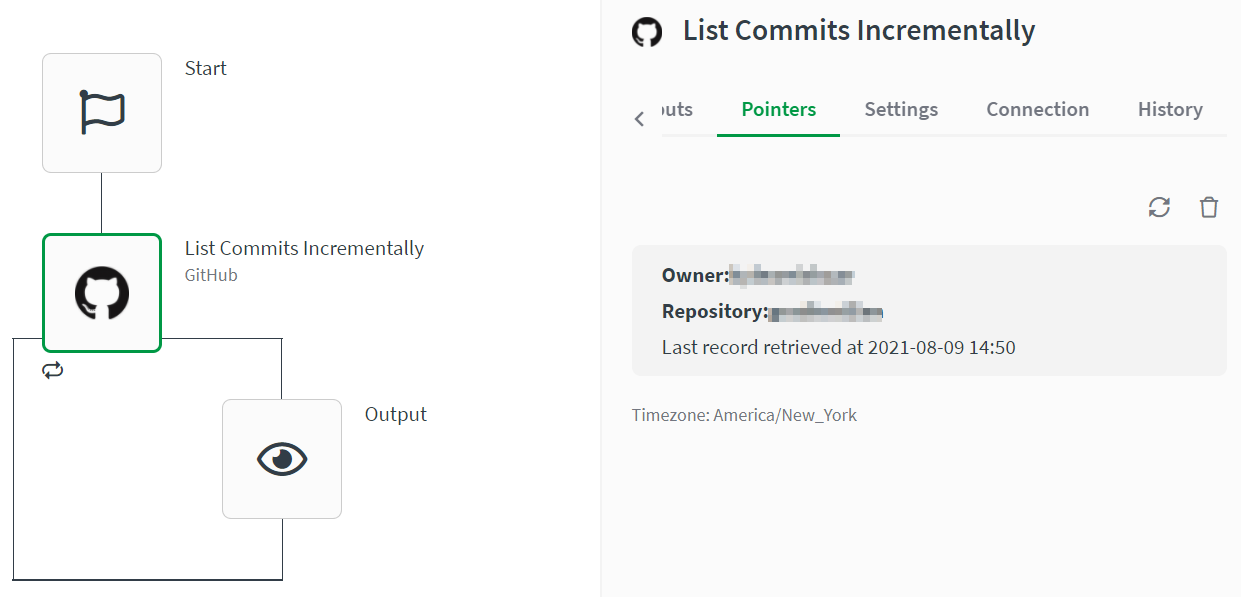
Incrementing the pointer
The pointer is incremented for each execution of the automation if a successful response was received from the API, even of the response was empty. If the API is down or did not respond with a 200 OK response code, the pointer will not be incremented. This means that on the next run, the API call sent with the same pointer so that you do not miss out on any data.
If the incremental endpoint received some data but the automation fails while looping over all the data, the pointer will still be increased.
If the API is down when the automation is executed, the automation will retry for up to five minutes. This means that downtime of an API under five minutes, it will not cause any issues in your automation.