
Prepare dataflow and commands sequence
Prepare enables data analysts to visualize and execute complex SQL and Pig transformations. Transform, Join, Router, Filter, Aggregation, Custom, Sort, Union, and Change Data Capture (CDC) are powerful controls on their own though combinations of these packages provide added flexibility and precision through serial transform operations.
Users drag and drop entities and transform controls to construct a graphical data model. The starting point(s) of each data flow graph is a source entity tile and each terminating point is a target entity. The package selected depends on the transformation required. Datasets then propagate from source to target via connectors that route data from the source entity output ports through the selected package where it is 'transformed' before being loaded and channeled into the target input port.
Do the following:
- Begin in Dataflow tab to modify an existing dataflow or click into the Designer tab to create a new dataflow on a fresh canvas.
-
From Designer, Click on Add Source from the command menu to bring up a list of available sources and entities.
Add source

-
Select one or more sources from the first screen.

-
Select the entities (contained within the sources chosen on the first screen) for the dataflow.
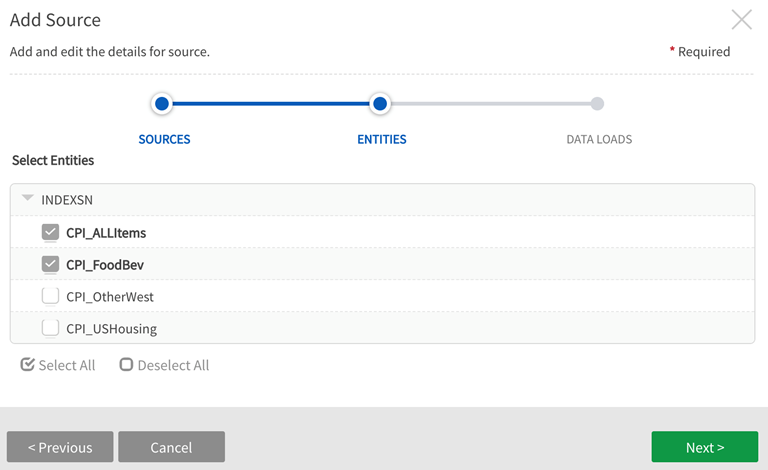
-
The next window presents entity base type options: Select All (Snapshot), Latest, Specific Loads (Incremental). Latest is the default selection to access one set of the data (the most recent load).
Add source - specify which dataloads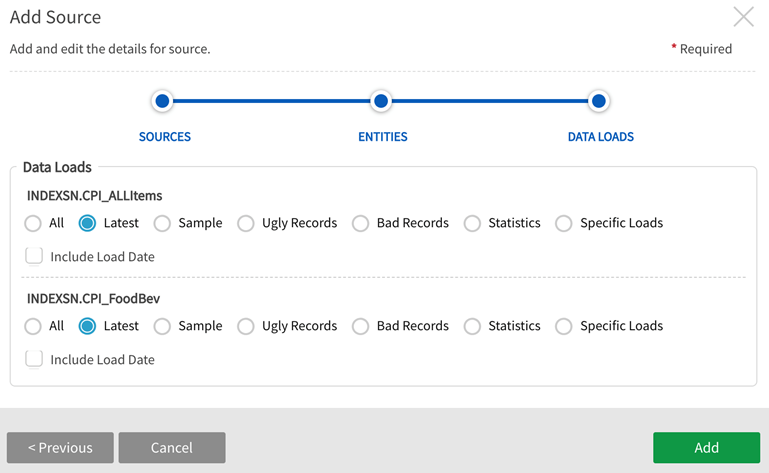 Information noteData load options All and Specific Loads are not enabled for Addressed and Registered entities.
Information noteData load options All and Specific Loads are not enabled for Addressed and Registered entities. -
Selected source entities appear on the canvas. Drag and drop the appropriate package icon onto the canvas; it will automatically become an executable package controller with input and output ports.
Drag and drop the package icon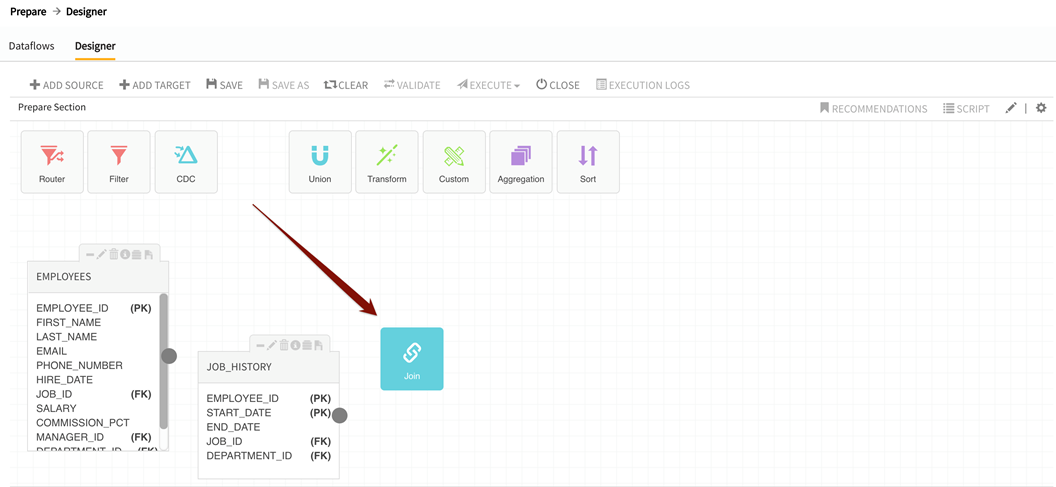
- Drag cursor from the round output port(s) on the source entity to the square input port of the package.
-
Double-click on the package controller to access relevant transform criteria for that controller.
Click on the package controller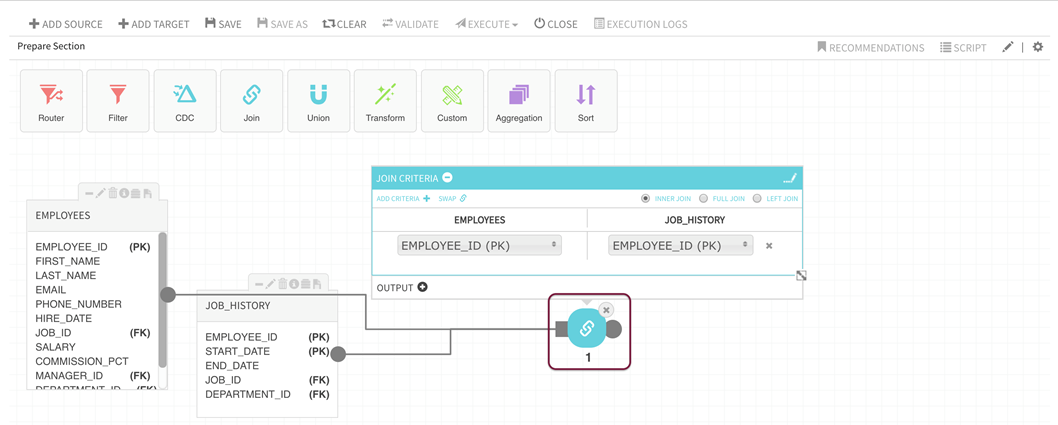
-
Refer to package-specific instructions for criteria definition and expression building.
-
Select Add Target in the command menu. This will bring up screen with information fields.

-
Configure the fields in the Add Target window that opens.
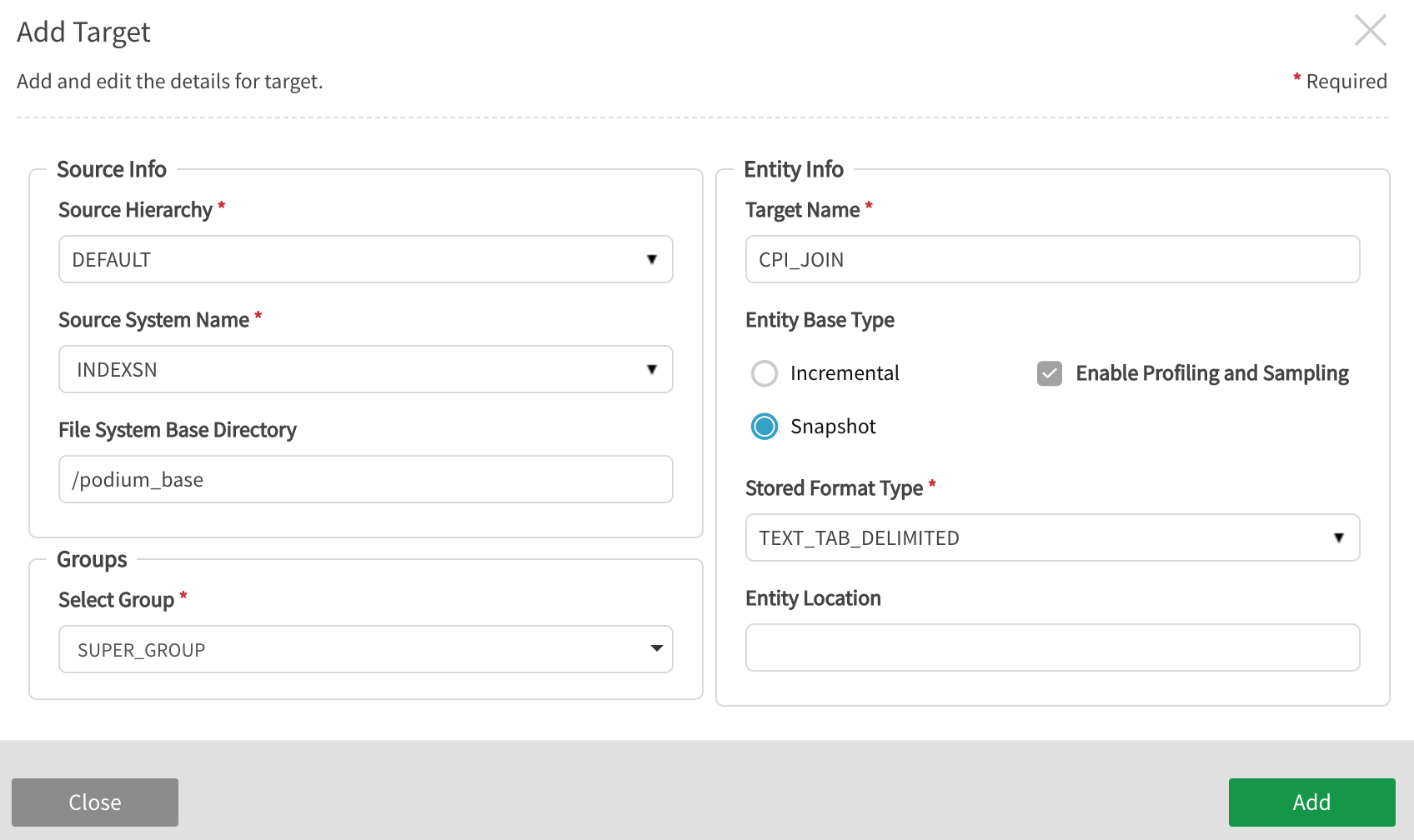
Source Hierarchy: Select the appropriate source hierarchy and source to save the target entity under.
Source System Name: Select the appropriate source folder for the target entity. This folder must be the same data source type: XML, JDBC, JSON, etc. A new folder can be created here by naming it.
Entity Info: Name the target entity by entering a name that is not already used for an entity in the source.
Entity Base Type: Select whether the dataload will be Snapshot (all data) or Incremental (default, data added since last load).
Enable Profiling: Prepare targets are not profiled by default. Default behavior is driven by enable.profiling property setting at source level. Note that users are also allowed to edit the value for this property on the target when the dataflow is executed.
Stored Format Type: Select desired storage format type: AVRO, ORC, ORC_ALL_STRING, PARQUET, PARQUET_ALL_STRING, TEXT_TAB_DELIMITED.
Entity Location gives administrators an additional layer of access control by enabling storage of sensitive entities in specific directories (example: '/hive/<database>/<sourcename>'). Hive location is optional.
Groups: Select Group(s) that require access to the new data from dropdown options. At least one group must be added for any user to be able to access the entity.
-
Drag the cursor from the round output port on the package to the square input port on the target entity.
Connect the package controller to the target entity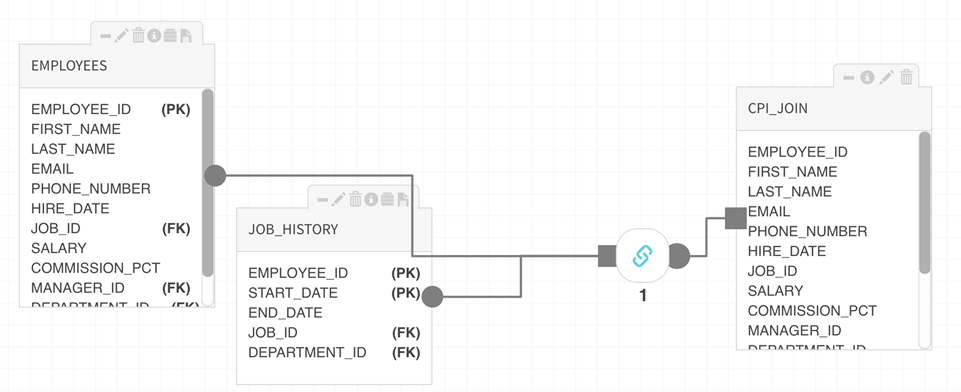
-
Save the dataflow or Save As to save a dataflow that has been modified or renamed. Dataflow MUST be named with an original name for the source.
Information notePrepare execution throws a syntax error if any field name is the same as a Pig keyword like 'LOAD'. The only temporary workaround is to rename the field but this will cause the next dataload to fail. See Apache documentation for Pig reserved keywords.Save and Delete behavior in Prepare
Source Entity
-
Saving: Navigating away from an unsaved dataflow canvas will result in loss of dataflow and associated objects. A pop-up displays warning the user that their data may be lost. When the user returns to the canvas the source entities will have disappeared if the dataflow has not been saved.
Target Entity
-
Saving: The target entity may be lost if a user navigates away and returns to the prepare canvas. The dataflow must be named and saved before navigating away from it, regardless of whether it has executed.
-
Deleting: If a target entity has been saved and the associated dataflow has executed when a user deletes it by selecting the trashcan delete icon, the target entity will disappear on the canvas; to delete the entity, it must be deleted from the discover grid. From the discover module, select Delete from More dropdown.
- The delete modal will display any dataflows that are impacted by the delete operation.
- The entity can be deleted from the dataflow designer screen and then re-selected by typing in the entity name while defining the target entity. A pop-up will confirm that the entity format matches with the existing definition.
Load Logs for Prepare Targets
- Prepare targets behave identically to other entities in regard to Load Type, Load Logs, and changes that can occur under the following circumstances.
- Load logs for a data entity have a column Load Type that is also displayed in the UI (in source module) The possible values are:
- DATA: The data was loaded as a Managed entity and all good/bad/ugly/profile/sample/log data is available.
- STATISTICS: The data was loaded as a Registered entity and profile/sample/log data is available.
- METADATA: This means only the metadata was refreshed as an Addressed entity. No data is available in file system or distribution table.
- STALE: This means the load log is no longer valid. Even if some data is available in the file system or distribution table, the load cannot be used in prepare or publish.
The load type can change for a load log under these circumstances:
- If a Managed entity is demoted to a Registered entity, all load logs with load type DATA are updated to load type Statistics, so only sample and profile data are available for that partition. The original load type is still available in the load log details.
- If a Managed or Registered entity is demoted to an Addressed entity, all its load logs with load type DATA/STATISTICS are updated to load type STALE and no data is available for that partition. The original load type is still available in the load log details.
- Deletion of source, entity or load logs: If user only deletes File System data and/or Table structure from popup options but keeps the object metadata (does not delete the object), then all load logs for entities are updated to load type STALE and no data is available for the affected partitions. The original load type is still available in the load log details.
Dataflow
- Saving: Save a new dataflow or replace a modified dataflow by saving and naming it.
- To make a copy of a dataflow Save As a new name.
- Clear: To display a blank canvas without deleting a dataflow, select Clear.
- Deleting: Dataflows can be deleted in the Dataflow tab. Select the dataflow row and then select Delete from the dropdown menu.
-
-
Once the dataflow has been saved successfully, Validate the package, then Execute the transform and data load. Some package expressions will already have been validated as part of their definition; always validate the dataflow before executing the transformation.
When users execute an unsaved dataflow; a dialog pops up asking if the dataflow should be saved. If a dataflow has been modified by the user but they don't want to save the modifications and they want to use the older saved version of data flow – they can opt to not save and execute the old/saved data flow or they can opt to save the modifications and execute the new dataflow.
-
After the syntax and dataflow are successfully validated, Execute the dataflow by selecting the appropriate engine with which to execute the transformation. Single node environments do not provide engine options; all dataflows are executed as Local. In these environments, simply click Execute.
Information noteOnly LOCAL mode is supported for Single Server Environments.
-
As the transform executes, execution status screen opens with status, click Reload to display updated status.
-
Once a dataflow has executed successfully, it can be closed.
Clear: Clears all dataflow components for a blank designer canvas.
Execution logs are available for any dataflow on the designer canvas that has executed. Execution logs are also available by highlighting the row in Dataflow tab and selecting Execution logs in the command menu.
Load types
Availability of load type is dictated by entity type. Load types that are not available for the selected entity are disabled.
| Load type | Entity Type Availability/Limitation | Load Type Description |
|---|---|---|
|
All |
Available for MANAGED entities |
Incremental base type—all incremental loads. This load type will include the entire dataset. |
|
Latest |
Available for all entity types except for USER_VIEWS |
Snapshot base type— full snapshot of the entity. |
|
Sample |
Available for entity types except for USER_VIEWS |
Per record.sampling.probability=.01 (default) applied at core_env, source or entity. If the entity has sample records in its latest load, those will be loaded when selecting this option. If there are no sample records, the data flow will fail validation. Only sample records from the latest load can be loaded and no previous history is available for selection. The fields of sample data are the same as the entity fields. This option is useful for validating dataflows on smaller samples before executing them on whole data set. |
|
Ugly Records |
Available for all entity types except for USER_VIEWS |
Collection of records with problematic field data such as data type inconsistency or embedded control characters. If the entity has Ugly records in its latest load, those will be loaded into the dataflow when selecting this option. If there are no ugly records, the dataflow will fail validation if this selection is used. Only ugly records from the latest load can be loaded and no previous history is available for selection. The fields of sample data are the same as the entity fields however all field types are STRING. This option is useful for fixing errors in ugly data. |
|
Bad Records |
Available for all entity types except for USER_VIEWS |
Collection of records that do not conform to specified record layout. If the entity has Bad records (record structure conflict exists where loaded data does not meet specification) in its latest load, those will be loaded in dataflow when selecting this option. If there are no bad records, the dataflow will fail validation if this selection is used. Only bad records from the latest load can be loaded and no previous history is available for selection. This load has a single field record of type STRING. This option is useful for fixing errors in the bad data. |
|
Statistics |
Available for all entity types except for USER_VIEWS |
Profile statistics from the latest load are loaded when this option is selected. Only statistics from the latest load can be loaded and no previous history is available for selection. The loader has 6 fields: entity_nid (INTEGER), field_nid (INTEGER), field_name (STRING), profile_metric (STRING), field_value (STRING), metric_value (STRING). Note that the entity_nid, field_nid and field_name refer to the nids and names of the external entity and fields respectively and not the internal entity/fields. This option is useful for exploring and mining profile statistics. See below for example of sample data for a statistics load. |
|
Specific Loads |
Available when entity is not USER_VIEW and is MANAGED |
One or more specific data loads of either type Incremental or Snapshot. Specific Loads include entity records from a specific partition (listed by load datetime). |
Sample data for statistics load
