Aggregation
Aggregation transforms source data by grouping on fields and aggregating through conditional operators.
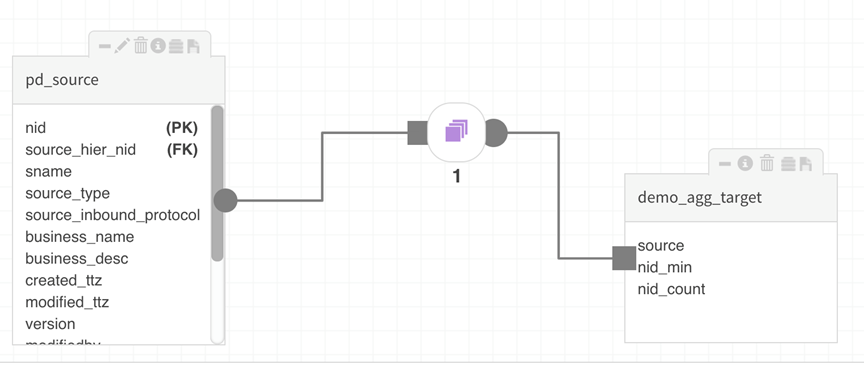
Once source entities are added to the canvas, the Aggregation package is brought onto the canvas by double-clicking or dragging the icon. When the square icon becomes a live controller on the canvas, double-click to reveal GROUP BY and AGGREGATE criteria for the operation.


GROUP BY gathers all discrete field values grouped by the field that has been indicated, then aggregated based on AGGREGATE functions such as AVG, COUNT, COUNT_STAR, MAX, MIN, SUM applied to that field.
When defining GROUP BY and AGGREGATE the field is first selected in the GROUP BY panel and then aggregated by function in the AGGREGATE panel. This control works similarly to a pivot chart where a user can summarize and analyze data by fields or groups of fields.
For this example, values grouped by the field: 'source_type' 0 target output 'source' (user-defined name) return values that will be GROUPED BY source (protocol) type.
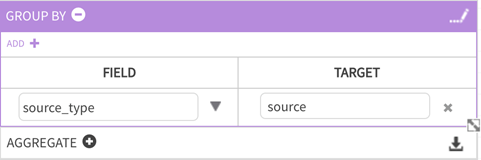
The second part of the definition applies AGGREGATION functions to selected fields (that will be grouped by the field selected in the top GROUP BY panel).
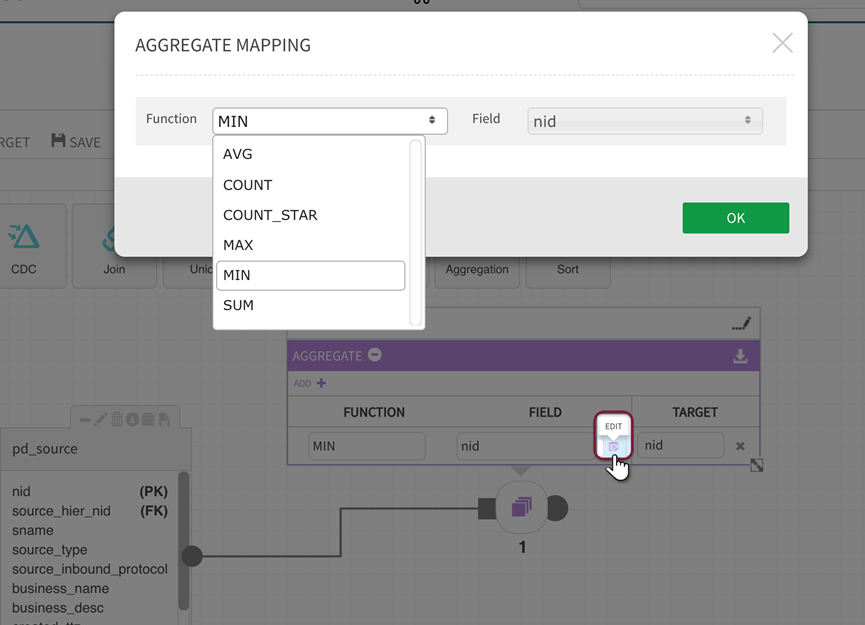
AGGREGATE returns a single result from multiple input rows and supports the following functions:
| Aggregation functions | Syntax | Description |
|---|---|---|
|
AVG |
(LONG|DOUBLE|DECIMAL) |
Computes the average of numeric values. The AVG function ignores NULL values. |
|
COUNT |
(EXPRESSION) of any type |
Computes the number of elements EXCLUDING NULL values. |
|
COUNT_STAR |
(EXPRESSION) of any type |
Computes the number of elements INCLUDING NULL values. |
|
MAX |
(LONG|DOUBLE|DECIMAL) |
Computes the maximum of the numeric values or char arrays in a single-column. |
|
MIN |
(LONG|DOUBLE|DECIMAL) |
Computes the minimum of the numeric values in a single-column. |
|
SUM |
(LONG|DOUBLE|DECIMAL) |
Computes the sum of the numeric values in a single-column. |
For the following example, the AGGREGATE function will return Minimum ID MIN value and total COUNT of source IDs in the target fields 'nid_min' and 'nid_count' the results will be grouped by source type. [Ensure that target fields have different names by renaming them when applying different functions to distinguish the values and avoid duplicate field name errors.]
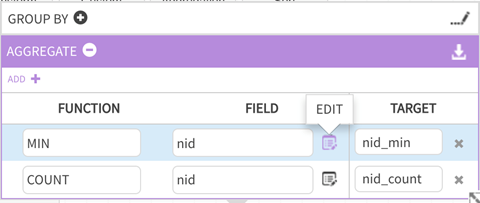
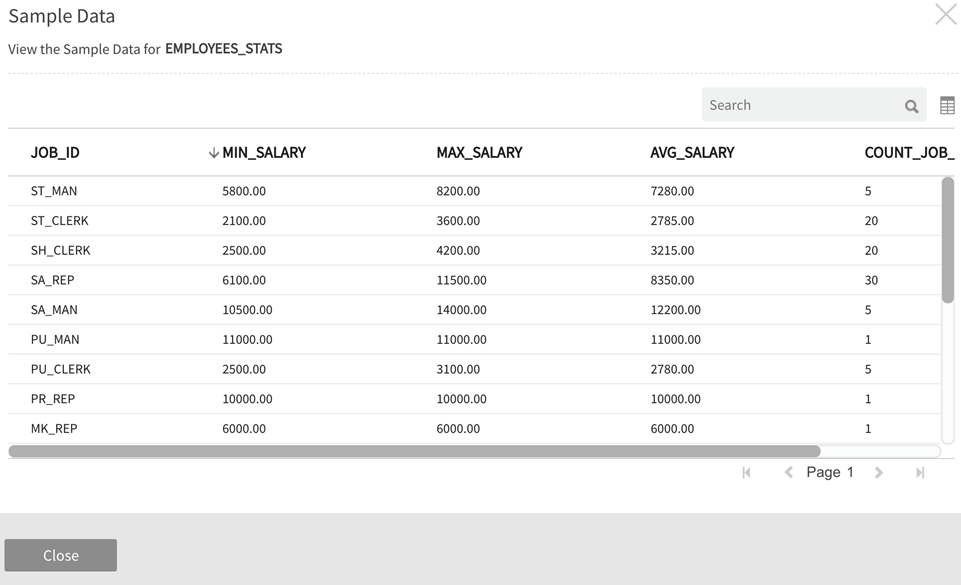
Save the dataflow, Validate the package, then Execute the data load into the target entity. In this example, sample data shows output (demo_agg_target) of the Aggregation operation, where values are grouped by 'source' type and AGGREGATE returns Minimum ID MIN value ('nid_min') and total COUNT of Source IDs ('nid_count') for the grouped source types.
CSV upload for Aggregation
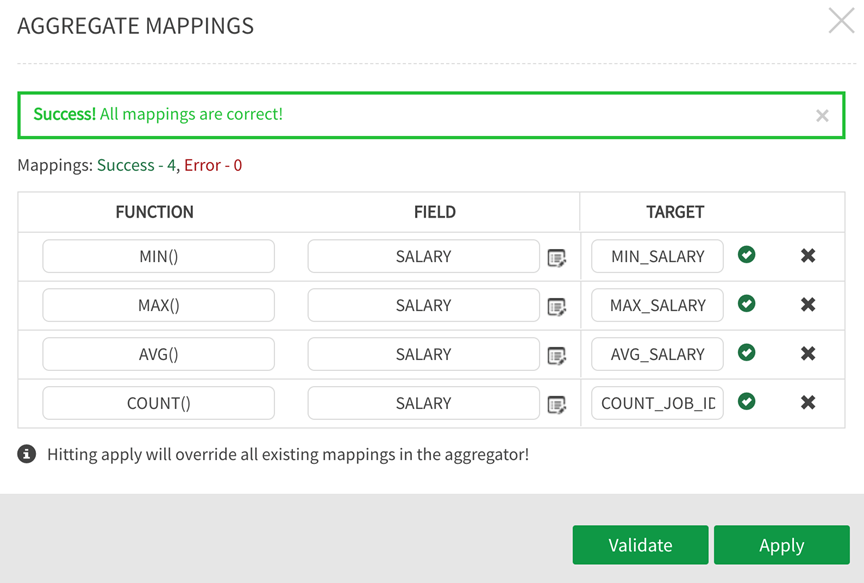
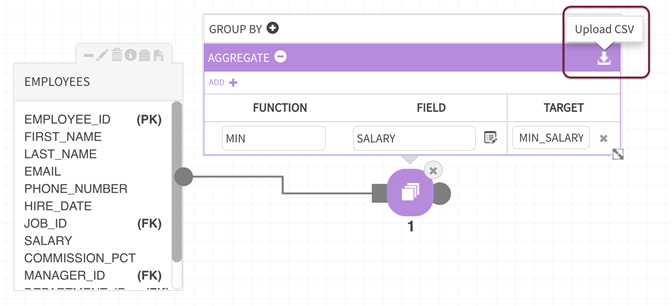
Analysts may need to re-use defined groupings and aggregates for replicating transformations across different sources and entities. For these use cases, upload a pre-built CSV from your local machine to generate the desired aggregations. The following example illustrates an uploaded set of expressions where a source file (EMPLOYEES) is grouped by job title ('JOB_ID') in the GROUP BY panel and output fields are defined applying the following functions to understand salaries against job title ('JOB_ID' )with values: MIN ('MIN_SALARY'), MAX ('MAX_SALARY'), AVG ('AVG_SALARY') salaries, and COUNT of employees belonging to each JOB ID.
Select Aggregation Control pull it onto the canvas, attach it to the source and entity, and GROUP BY 'JOB_ID'.
Select the CSV file on your local machine for Upload. CSVs are created by listing Function (column A), Field (column B), and Target (COLUMN) exactly as they would be entered manually in the aggregate mappings fields.
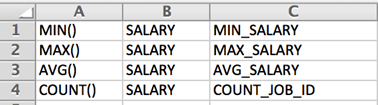
The CSV populates the fields. If the application encounters mismatched fields or inaccuracies, errors will indicate which fields do not map correctly. Validate the mappings, select Apply.