
ファンクションアーキテクチャー
次の図は、とのファンクションアーキテクチャーを示したものです。

次の図は、とのファンクションアーキテクチャーを示したものです。
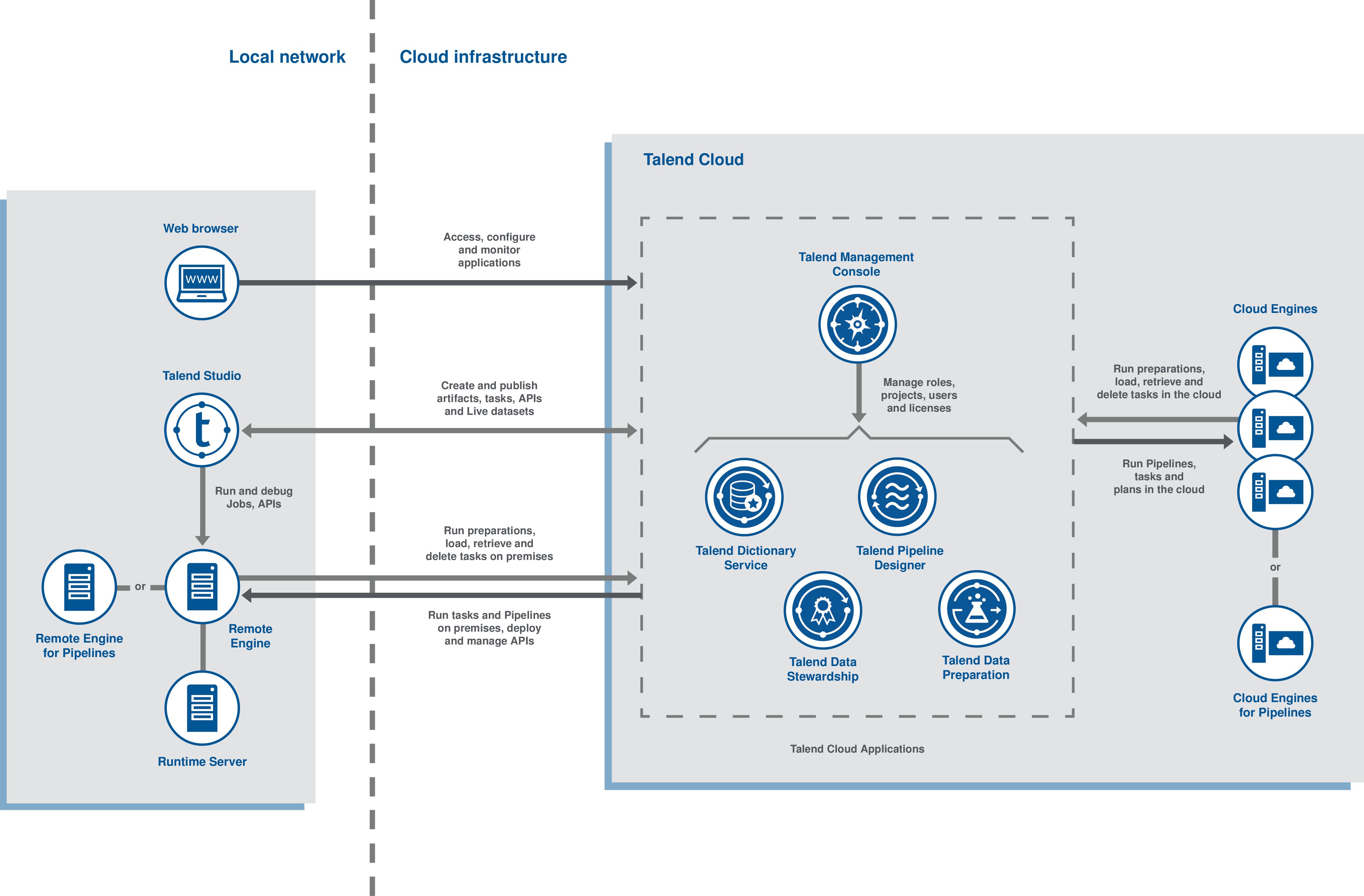
次の図は、、、のファンクションアーキテクチャーを示したものです。
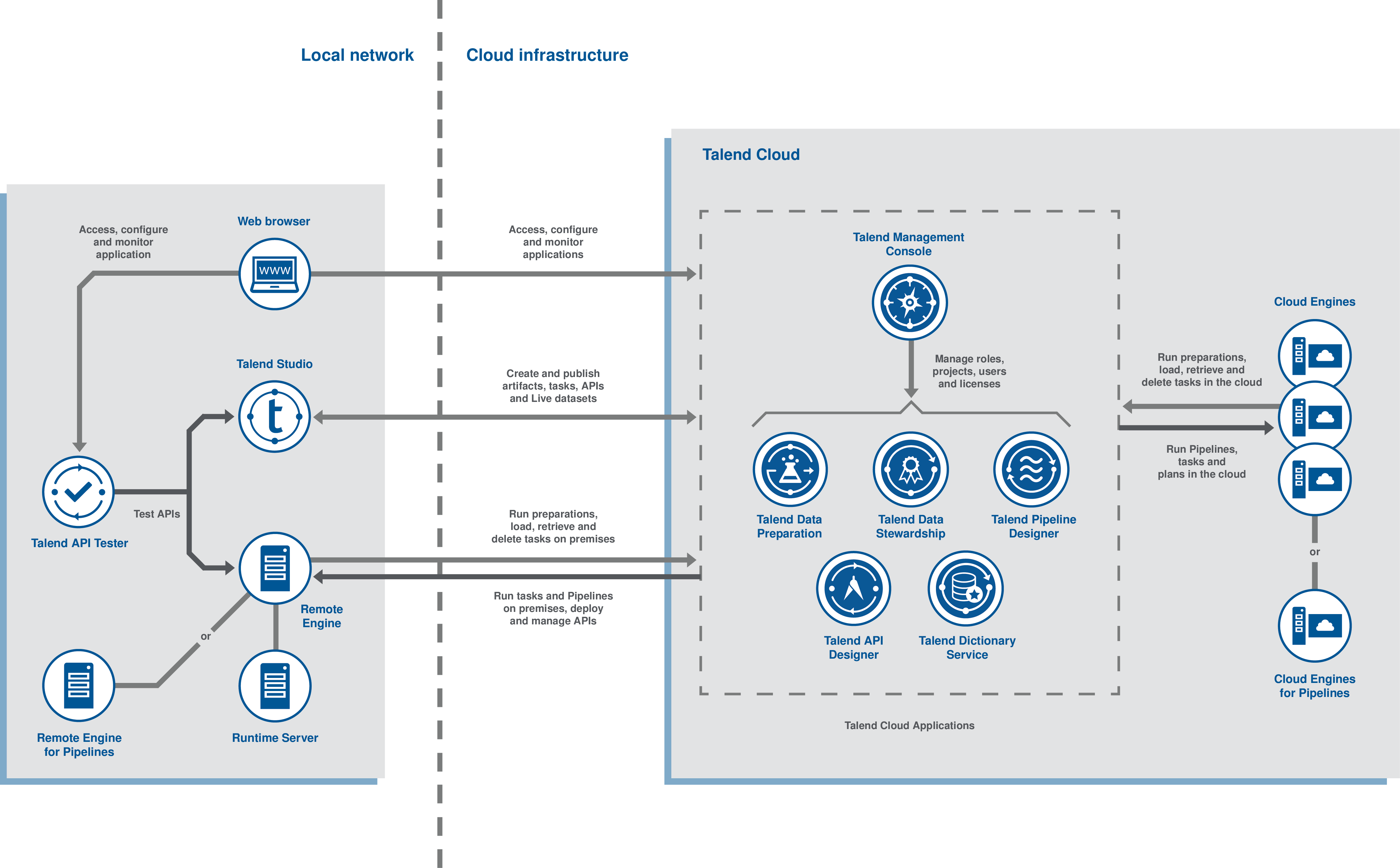
ファンクションアーキテクチャーの図は、ローカルネットワークとクラウドインフラストラクチャーという2つの主要な部分に分かれています。
ローカルネットワーク
ローカルネットワークには、Webブラウザー、、およびRemote Engineとのいずれかが含まれています。
-
Webブラウザーから、さまざまなクラウドアプリケーションにアクセスできます。
- では次の操作が可能です。
- データ統合ジョブ、ルート、サービスをタスクとしてに公開し、Webユーザーが利用できるようにしてクラウドで実行する。
- tDatasetInput、tDatasetOutput、tDataprepRunの各コンポーネントを使って、の機能を利用する。さまざまなデータセットからデータセットを作成してにエクスポートしたり、データ統合ジョブまたはSparkジョブでプレパレーションを直接利用したりできます。
- tDataStewardshipTaskOutput、tDataStewardshipTaskInput、tDataStewardshipTaskDeleteを伴うジョブを使って、で作成されたキャンペーンのタスクをロード、取得、削除する。
- API定義をから直接インポートし、サービスの実装に使用する。その後はをテストし、に公開できます。
-
は、オンプレミスでのジョブ、タスク、プレパレーションの実行に使用されます。は、あらゆる場所(オンプレミスまたは仮想プライベートクラウド)でのパイプラインの実行に使用されます。
がと同じマシンで実行されている場合は、ルート、データサービス、タスクをオンプレミスで実行することもできます。
- で、リクエストとシナリオを作成またはインポートしてAPIをテストできます。Mavenプラグインを使ってテストを自動化することもできます。
クラウドインフラストラクチャー
クラウドインフラストラクチャーには、クラウドアプリケーションとCloud Engineが含まれます。
- では、ロール、ユーザー、プロジェクト、およびアクセスライセンス情報を管理できます。クラウドアプリケーションの新しいユーザーを作成し、カスタムグループに割り当てます。その後、ロールを決定し、ユーザーに割り当てることができます。はライセンスファイルを保存し、で共同作業するプロジェクトの作成が可能になります。加えて、Webユーザーのデータおよびファイル転送、データ統合、および共有データソースへのアクセスを有効にできます。たとえば、アプリケーション間のデータ交換と同期を自動化する、設定済みのサンプルタスクまたはデザインタスクをインポートして使用できます。
- では、保存データや実行データの処理、エンリッチ化、変換を行うために、複雑なエンドツーエンドのパイプラインをデザインできます。これらのパイプラインは、組み込みの、またはVirtual Private Cloudやオンプレミスにインストールされているを使って実行できます。
- では、ローカルファイルやその他のソースからデータをインポートし、新しいプレパレーションを作成することでクレンジングまたはエンリッチ化できます。
- では、キャンペーン所有者はデータアセットを管理し、データのキュレーション、調停、検証に関する共同作業が必要な場合にデータのやり取りを整理します。
- では、またはで開いた場合に、データの各カラムに適用されるセマンティックカテゴリーを追加、削除、変更できます。
- では、APIをデザインしたり、既存の定義をインポートし、そのドキュメンテーションを公開してモックを作成できます。その後、OpenAPI仕様/SwaggerまたはRAMLで定義をエクスポートします。また、デザインのどのステップでもでAPIをテストできます。
Cloud Engineは、クラウドのアーティファクト、タスク、プレパレーション、パイプラインを実行するために使用されます。
ルートとデータサービスは、Remote Engine/実行時にのみデプロイできます。