
ビッグデータ
| 機能 | 説明 | 対象製品 |
|---|---|---|
| 標準ジョブでIcebergコンポーネントによるブランチングとタグ付けをサポート | 標準ジョブのtIcebergTableで、Icebergテーブルのブランチやタグに対してアクションを実行できるようになりました。[Alter table action] (テーブルアクションを変更)ドロップダウンリストに新しいパラメーターが追加され、ブランチやタグを作成または削除できるようになりました。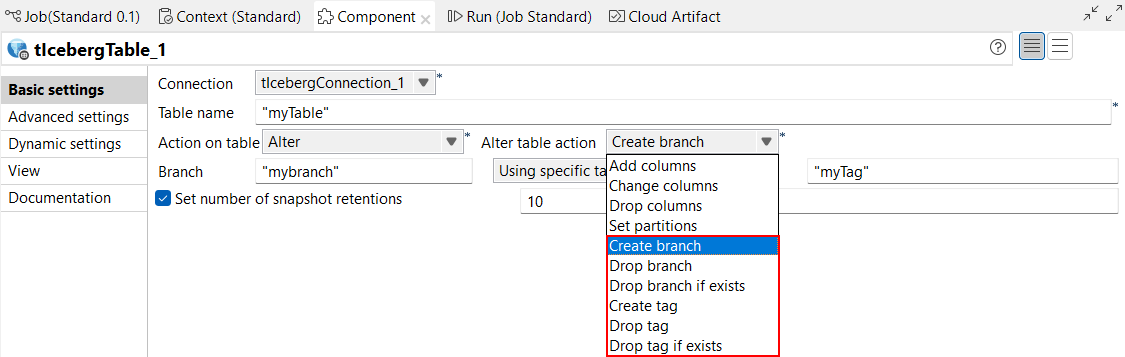
|
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
| Sparkジョブで出力ファイル書き込み時の並列化をサポート | Spark Batchジョブの[Spark configuration] (Spark設定)ビューに、[Parallelize output files writing] (出力ファイルの書き込みを並列化)という新しいオプションが追加されました。このオプションを選択すると、Spark Batchジョブが出力ファイルを書き込む時に、1つのスレッドで順次書き込むのではなく、複数のスレッドを並行して実行するようになります。 このオプションによって実行時間のパフォーマンスが改善されます。 このオプションは、次の出力コンポーネントが含まれているSparkバッチジョブでのみ使用できます:

|
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
| 標準ジョブでHiveコンポーネントとのHDInsight接続モードをサポート | 標準ジョブでADLS Gen1を使用するHiveコンポーネントで、HDInsightのバージョン5.0と5.1がサポートされるようになりました。 |
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
| Spark Universal 3.3.xでHDInsight 5.1をサポート | Spark Universal 3.3.xを使い、HDInsightでSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。この設定は、Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードでADLS Gen2ストレージまたはAzureストレージを使って実行できます。 このモードを選択すると、Talend StudioはHDInsight 5.1バージョンと互換性を持つようになります。 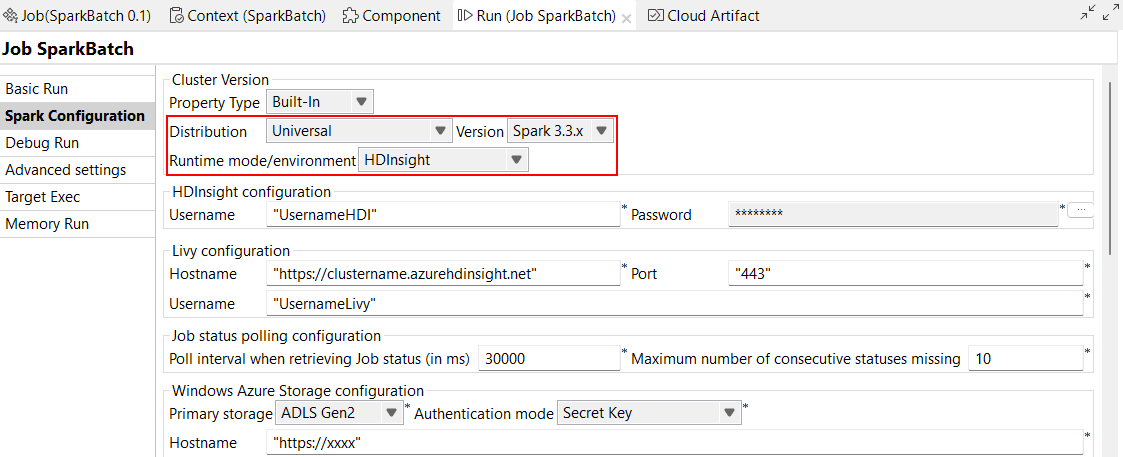
|
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |