
ビッグデータ
| 機能 | 説明 | 対象製品 |
|---|---|---|
| Spark Universal 3.5.xでローカルモードをサポート | [Local] (ローカル)モードのSpark 3.5.xで、Spark Universalを使ってSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 |
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
| CDP Public Cloud Data Hub 7.2.17とSpark Universal 3.3.xをサポート | Spark 3.3.xと共にSpark Universalを使って、AWSによるCDP Public Cloud Data HubでSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 このモードを選択すると、Talend StudioはCDP Public Cloud Data Hub 7.2.17バージョンと互換性を持つようになります。 この機能では、HBaseとKnox認証はサポートされていません。 |
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
| Spark Universal 3.1.xでHDInsight 5.0をサポート | Spark Universal 3.1.xを使い、HDInsightでSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。この設定は、Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードでADLS Gen2ストレージまたはAzureストレージを使って実行できます。 このモードを選択すると、Talend StudioはHDInsight 5.0バージョンと互換性を持つようになります。 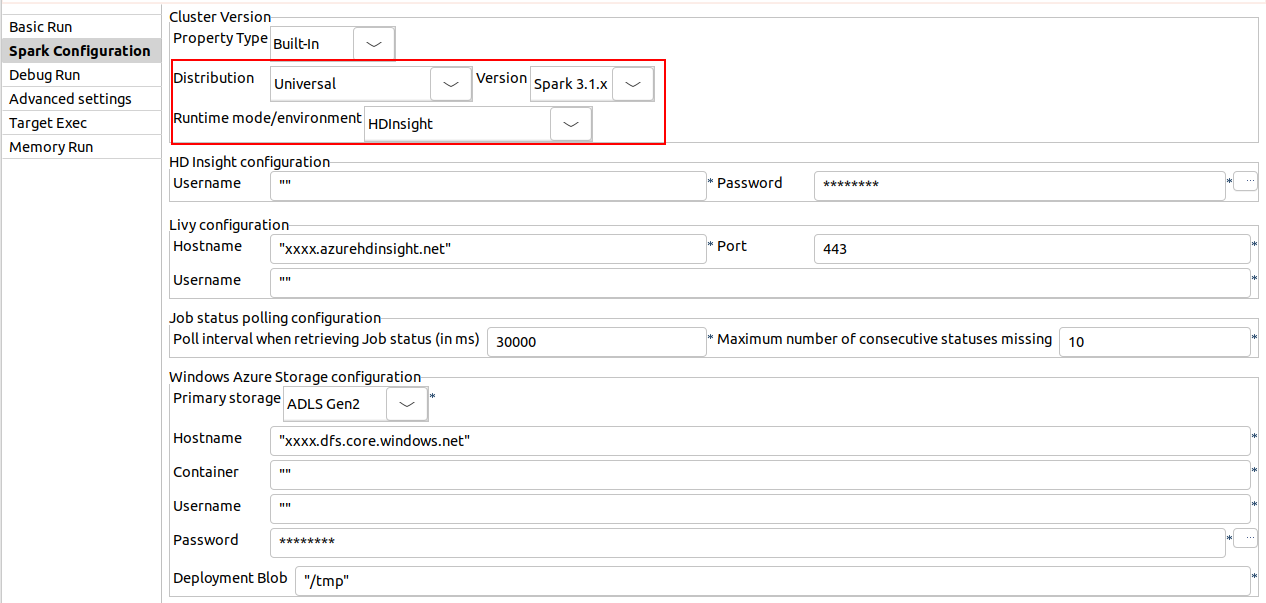
|
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |