
Splitting the input data flow
At the end of this link, Talend Studio automatically collects the split thread to accomplish the collecting step.
Configuring the input flow
Procedure
-
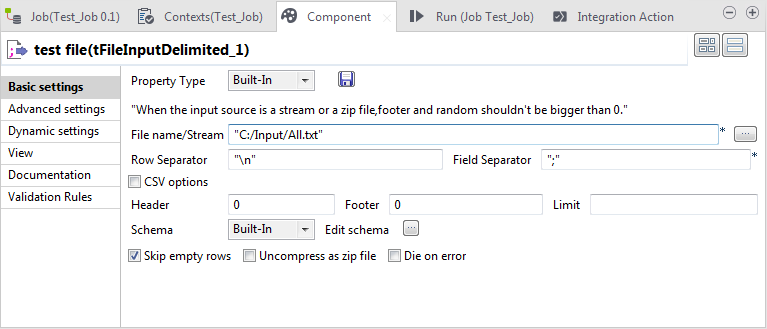
Double-click tFileInputDelimited to
open its Component view.
-
Click the
 button to open the schema editor where you need to create the schema to
reflect the structure of the customer data.
button to open the schema editor where you need to create the schema to
reflect the structure of the customer data.
-
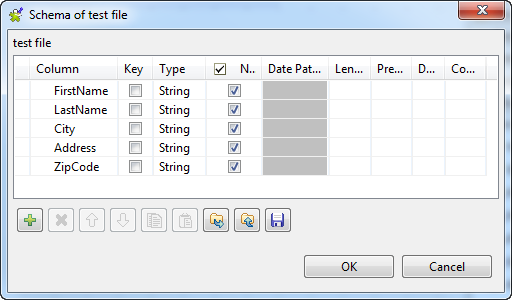
Click the
 button five times to add five rows and rename them as follows:
FirstName, LastName,
City, Address and
ZipCode.
In this scenario, we leave the data types with their default value String. In the real-world practice, you can change them depending on the data types of your data to be processed.
button five times to add five rows and rename them as follows:
FirstName, LastName,
City, Address and
ZipCode.
In this scenario, we leave the data types with their default value String. In the real-world practice, you can change them depending on the data types of your data to be processed.
Configuring the partitioning step
Procedure
-
Click the link representing the partitioning step to open its
Component view and click the
Parallelization tab.
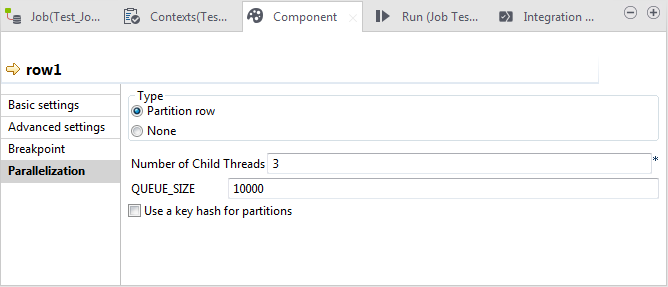 The Partition row option has been automatically selected in the Type area. If you select None, you are actually disabling parallelization for the data flow to be handled over this link. Note that depending on the link you are configuring, a Repartition row option may become available in the Type area to repartition a data flow already departitioned.In this Parallelization view, you need to define the following properties:
The Partition row option has been automatically selected in the Type area. If you select None, you are actually disabling parallelization for the data flow to be handled over this link. Note that depending on the link you are configuring, a Repartition row option may become available in the Type area to repartition a data flow already departitioned.In this Parallelization view, you need to define the following properties:- Number of Child Threads: the number of threads you want to split the input records up into. We recommend that this number be N-1 where N is the total number of CPUs or cores on the machine processing the data.
- Buffer Size: the number of rows to cache for each of the threads generated.
-
Use a key hash for partitions: this allows you to use the
hash mode to dispatch the input records into threads.
Once selecting it, the Key Columns table appears, in which you set the column(s) you want to apply the hash mode on. In the hash mode, the records meeting the same criteria are dispatched into the same threads.
If you leave this check box clear, the dispatch mode is Round-robin, meaning records are dispatched one-by-one to each thread, in a circular fashion, until the last record is dispatched. Be aware that this mode cannot guarantee that records meeting the same criteria go into the same threads.