Configuring the connection manually
About this task
Even though importing a given Hadoop configuration is always an efficient way, you may have to set up the connection manually in some circumstances, for example, you do not have the configurations you can import at hand.
Procedure
-
Fill in the fields that become activated depending on the
version info you have selected.
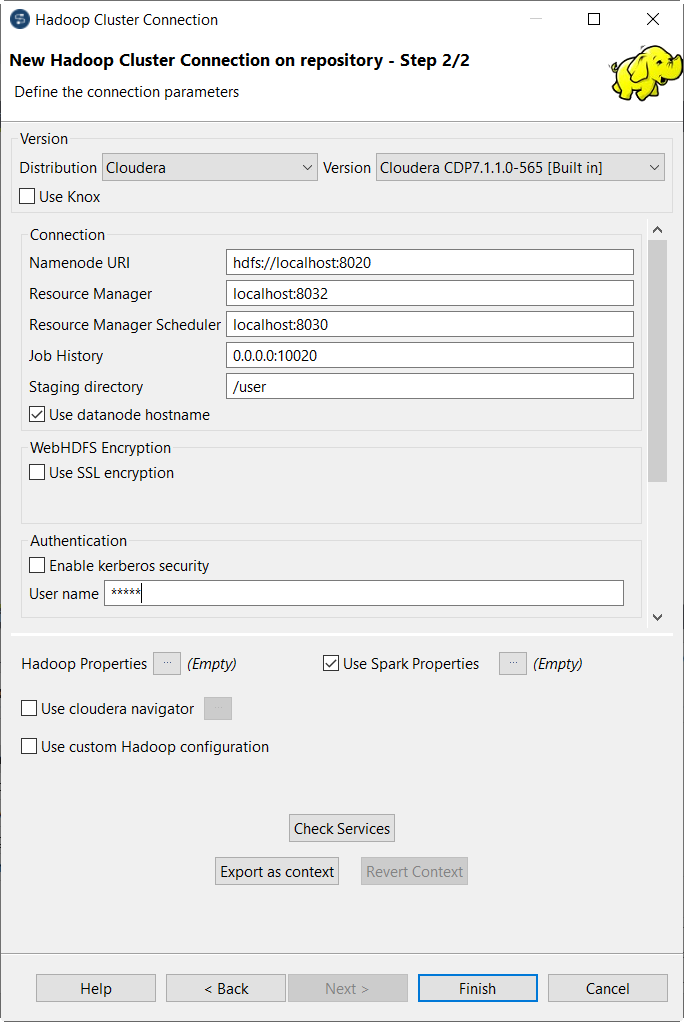
Note that among these fields, the NameNode URI field and the Resource Manager field have been automatically filled with the default syntax and port number corresponding to the selected distribution. You need to update only the part you need to depending on the configuration of the Hadoop cluster to be used. For further information about these different fields to be filled, see the following list.
 Those fields may be:
Those fields may be:-
Namenode URI:
Enter the URI pointing to the machine used as the NameNode of the Hadoop distribution to be used.
The NameNode is the main node of a Hadoop system. For example, assume that you have chosen a machine called machine1 as the NameNode of an Apache Hadoop distribution, then the location to be entered is hdfs://machine1:portnumber.
If you are using WebHDFS, the location should be webhdfs://masternode:portnumber; WebHDFS with SSL is not supported yet.
If you are using a MapR distribution, you can simply leave maprfs:/// as it is in this field; then the MapR client will take care of the rest on the fly for creating the connection. The MapR client must be properly installed. For further information about how to set up a MapR client, see MapR documentation.
-
Resource Manager:
Enter the URI pointing to the machine used as the Resource Manager service of the Hadoop distribution to be used.
Note that in some older Hadoop distribution versions, you need to set the location of the JobTracker service instead of the Resource Manager service.
Then you need to set further the addresses of the related services such as the address of the Resourcemanager scheduler. When you use this connection in a Big Data relevant component such as tHiveConnection, you will be able to allocate memory to the Map and the Reduce computations and the ApplicationMaster of YARN in the Advanced settings view. For further information about the Resource Manager, its scheduler and the ApplicationMaster, see the documentation about YARN for your distribution.
-
Job history:
Enter the location of the JobHistory server of the Hadoop cluster to be used. This allows the metrics information of the current Job to be stored in that JobHistory server.
-
Staging directory:
Enter this directory defined in your Hadoop cluster for temporary files created by running programs. Typically, this directory can be found under the yarn.app.mapreduce.am.staging-dir property in the configuration files such as yarn-site.xml or mapred-site.xml of your distribution.
-
Use datanode hostname:
Select this check box to allow the Job to access datanodes via their hostnames. This actually sets the dfs.client.use.datanode.hostname property to true. If this connection is going to be used by a Job connecting to a S3N filesystem, you must select this check box.
-
Enable Kerberos security:
If you are accessing a Hadoop distribution running with Kerberos security, select this check box, then, enter the Kerberos principal names for the NameNode in the field activated.
These principals can be found in the configuration files of your distribution. For example, in a CDH4 distribution, the Resource manager principal is set in the yarn-site.xml file and the Job history principal in the mapred-site.xml file.
If you need to use a keytab file to log in, select the Use a keytab to authenticate check box. A keytab file contains pairs of Kerberos principals and encrypted keys. You need to enter the principal to be used in the Principal field and in the Keytab field, browse to the keytab file to be used.
Note that the user that executes a keytab-enabled Job is not necessarily the one a principal designates but must have the right to read the keytab file being used. For example, the username you are using to execute a Job is user1 and the principal to be used is guest; in this situation, ensure that user1 has the right to read the keytab file to be used.
-
If you are connecting to a MapR cluster V4.0.1 and onwards and the MapR ticket security system of the cluster has been enabled, you need to select the Force MapR Ticket Authentication check box and define the following parameters:
- In the Password field, specify the password used by
the user for authentication.
A MapR security ticket is generated for this user by MapR and stored in the machine where the Job you are configuring is executed.
- In the Cluster
name field, enter the name of the MapR cluster
you want to use this username to connect to.
This cluster name can be found in the mapr-clusters.conf file located in /opt/mapr/conf of the cluster.
- In the Ticket duration field, enter the length of time (in seconds) during which the ticket is valid.
- Keep the Launch authentication mechanism when the Job starts check box selected in order to ensure that the Job using this connection takes into account the current security configuration when it starts to run.
If the default security configuration of your MapR cluster has been changed, you need to configure the connection to take this custom security configuration into account.
MapR specifies its security configuration in the mapr.login.conf file located in /opt/mapr/conf of the cluster. For further information about this configuration file and the Java service it uses behind, see MapR documentation and JAAS.
Proceed as follows to do the configuration:
- Verify what has been changed about this
mapr.login.conf
file.
You should be able to obtain the related information from the administrator or the developer of your MapR cluster.
- If the location of the MapR configuration files has been changed to somewhere else in the cluster, that is to say, the MapR Home directory has been changed, select the Set the MapR Home directory check box and enter the new Home directory. Otherwise, leave this check box clear and the default Home directory is used.
- If the login module to be used in the
mapr.login.conf file
has been changed, select the Specify
the Hadoop login configuration check box and
enter the module to be called from the mapr.login.conf file.
Otherwise, leave this check box clear and the default login
module is used.
For example, enter kerberos to call the hadoop_kerberos module or hybrid to call the hadoop_hybrid module.
- In the Password field, specify the password used by
the user for authentication.
-
User name:
Enter the user authentication name of the Hadoop distribution to be used.
If you leave this field empty, Talend Studio will use your login name of the client machine you are working on to access that Hadoop distribution. For example, if you are using Talend Studio in a Windows machine and your login name is Company, then the authentication name to be used at runtime will be Company.
-
Group:
Enter the group name to which the authenticated user belongs.
Note that this field becomes activated depending on the distribution you are using.
-
Hadoop properties:
If you need to use custom configuration for the Hadoop distribution to be used, click the [...] button to open the properties table and add the property or properties to be customized. Then at runtime, these changes will override the corresponding default properties used by Talend Studio for its Hadoop engine.
Note that the properties set in this table are inherited and reused by the child connections you will be able to create based on this current Hadoop connection.
For further information about the properties of Hadoop, see Apache's Hadoop documentation, or the documentation of the Hadoop distribution you need to use. For example, this page lists some of the default Hadoop properties.
For further information about how to leverage this properties table, see Setting reusable Hadoop properties.
- Use Spark Properties: select the Use Spark properties check box to open the properties table and add the property or properties specific to Spark configuration you want to use, for example, from spark-defaults.conf of your cluster.
-
When the distribution to be used is Microsoft HD Insight, you need to set the WebHCat configuration for your HD Insight cluster, the HDInsight configuration for the credentials of your HD Insight cluster and the Window Azure Storage configuration instead of the parameters mentioned above.
Parameter Description WebHCat configuration
Enter the address and the authentication information of the Microsoft HDInsight cluster to be used. For example, the address could be your_hdinsight_cluster_name.azurehdinsight.net and the authentication information is your Azure account name: ychen. Talend Studio uses this service to submit the Job to the HD Insight cluster.
In the Job result folder field, enter the location in which you want to store the execution result of a Job in the Azure Storage to be used.
HDInsight configuration
- The Username is the one defined when creating your cluster. You can find it in the SSH + Cluster login blade of your cluster.
- The Password is defined when creating your HDInsight cluster for authentication to this cluster.
Windows Azure Storage configuration
Enter the address and the authentication information of the Azure Storage or ADLS Gen2 account to be used. In this configuration, you do not define where to read or write your business data but define where to deploy your Job only.
In the Primary storage drop-down list, select the storage to be used.
If you want to secure the connection to the storage with TLS, select the use secure connection (TLS) check box.
In the Container field, enter the name of the container to be used. You can find the available containers in the Blob blade of the Azure Storage account to be used.
In the Deployment Blob field, enter the location in which you want to store the current Job and its dependent libraries in this Azure Storage account.
In the Hostname field, enter the Primary Blob Service Endpoint of your Azure Storage account without the https:// part. You can find this endpoint in the Properties blade of this storage account.
In the Username field, enter the name of the Azure Storage account to be used.
In the Password field, enter the access key of the Azure Storage account to be used. This key can be found in the Access keys blade of this storage account.
-
If you are using Cloudera V5.5+, you can select the Use Cloudera Navigator check box to enable the Cloudera Navigator
of your distribution to trace your Job lineage to the component level, including the
schema changes between components.
You need then to click the [...] button to open the Cloudera Navigator Wizard window to define the following parameters:
-
Username and Password: this is the credentials you use to connect to your Cloudera Navigator.
-
URL: enter the location of the Cloudera Navigator to be connected to
-
Metadata URL: enter the location of the Navigator Metadata.
-
Client URL: leave the default value as is.
-
Autocommit: select this check box to make Cloudera Navigator generate the lineage of the current Job at the end of the execution of this Job.
Since this option actually forces Cloudera Navigator to generate lineages of all its available entities such as HDFS files and directories, Hive queries or Pig scripts, it is not recommended for the production environment because it will slow the Job.
- Die on error: select this check box to stop the execution of the Job when the connection to your Cloudera Navigator fails. Otherwise, leave it clear to allow your Job to continue to run.
-
Disable
SSL: select this check box to make your Job to
connect to Cloudera Navigator without the SSL validation
process.
This feature is meant to facilitate the test of your Job but is not recommended to be used in a production cluster.
Once the configuration is done, click Finish to validate the settings.
-
-
-
Click Finish to
validate your changes and close the wizard.
The newly set-up Hadoop connection displays under the Hadoop cluster folder in the Repository tree view. This connection has no sub-folders until you create connections to any element under that Hadoop distribution.