
Replicating a flow and sorting two identical flows respectively
This scenario applies only to Talend products with Big Data.
The Job in this scenario uses Pig components to handle names and states loaded from a given HDFS system. It reads and replicates the input flow, then sorts the two identical flows based on name and state respectively, and writes the results back into that HDFS.
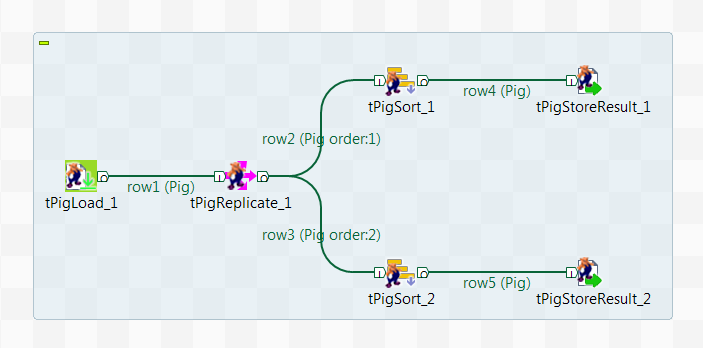
Before starting to replicate this Job, ensure that you have the appropriate right to read and write data in the Hadoop distribution to be used and that Pig is properly installed in that distribution.