
Joining data about road conditions in a Pig process
This scenario applies only to Talend products with Big Data.
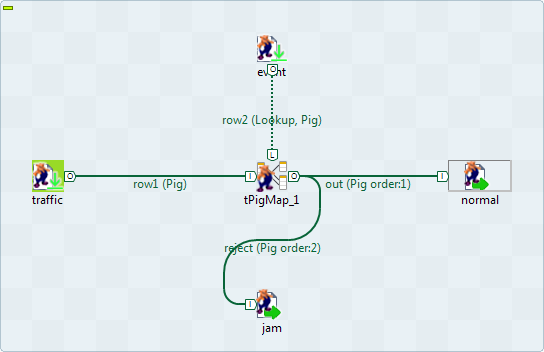
The Job in this scenario uses two tPigLoad components to read data about the traffic conditions and the related events on given roads from a given Hadoop distribution, joins and filters the data using tPigMap, and writes the results into that Hadoop distribution using two tPigStoreResult.
The Hadoop distribution to be used is keeping the data about traffic situation such as normal or jam and the data about the traffic-related events such as road work, rain and even no event. In this example, the data to be used reads as follows:
-
The traffic situation data stored in the directory /user/ychen/tpigmap/date&traffic:
2013-01-11 00:27:53;Bayshore Freeway;jam 2013-02-28 07:01:18;Carpinteria Avenue;jam 2013-01-26 11:27:59;Bayshore Freeway;normal 2013-03-07 20:48:51;South Highway;jam 2013-02-07 07:40:10;Lindbergh Blvd;normal 2013-01-22 17:13:55;Pacific Hwy S;normal 2013-03-17 23:12:26;Carpinteria Avenue;normal 2013-01-15 08:06:53;San Diego Freeway;jam 2013-03-19 15:18:28;Monroe Street;jam 2013-01-20 05:53:12;Newbury Road;normal -
The event data stored in the directory /user/ychen/tpigmap/date&event:
2013-01-11 00:27:53;Bayshore Freeway;road work 2013-02-28 07:01:18;Carpinteria Avenue;rain 2013-01-26 11:27:59;Bayshore Freeway;road work 2013-03-07 20:48:51;South Highway;no event 2013-02-07 07:40:10;Lindbergh Blvd;second-hand market 2013-01-22 17:13:55;Pacific Hwy S;no event 2013-03-17 23:12:26;Carpinteria Avenue;no event 2013-01-15 08:06:53;San Diego Freeway;second-hand market 2013-03-19 15:18:28;Monroe Street;road work 2013-01-20 05:53:12;Newbury Road;no event
For any given moment shown in the timestamps in the data, one row is logged to reflect the traffic situation and another row to reflect the traffic-related event. You need to join the data into one table in order to easily detect how the events on a given road are impacting the traffic.
The data used in this example is a sample with limited size.
To replicate this scenario, ensure that the Studio to be used has the appropriate right to read and write data in that Hadoop distribution and then proceed as follows: