
Aggregating data from two relations using COGROUP
This scenario applies only to Talend products with Big Data.
In this scenario, a four-component Job is designed to aggregate two relations on top of a given Hadoop cluster.
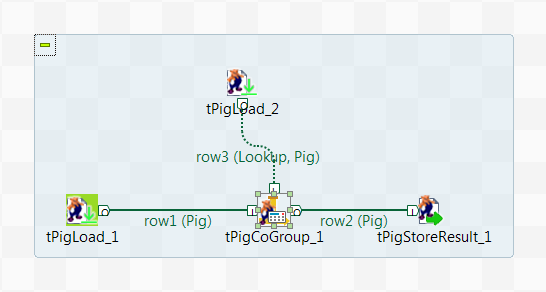
The two relations used in this scenario consist of the following sample data:
-
This relation is composed of three columns that read owner, pet and age (of the owners).
Alice,turtle,17 Alice,goldfish,17 Alice,cat,17 Bob,dog,18 Bob,cat,18 John,dog,19 Mary,goldfish,16 Bill,dog,20 -
This relation provides a list of students' names alongside their friends, of which some are pet owners displayed in the first relation. Therefore, the schema of this relation contains two columns: student and friend.
Cindy,Alice Mark,Alice Paul,Bob Paul,Jane John,Mary William,Bill
Before replicating this scenario, you need to write the sample data into the HDFS system of the Hadoop cluster to be used. To do this, you can use tHDFSOutput.
The data used in this scenario is inspired by the examples that Pig's documentation uses to explain the GROUP and the GOGROUP operators. For related information, please see Apache's documentation for Pig.