
Rodzina funkcji określanych jako funkcje agregacji składa się z funkcji pobierających wiele wartości pola jako dane wejściowe i zwracających jeden wynik na grupę. Grupowanie jest definiowane przez wymiar wykresu lub klauzulę group by w wyrażeniu skryptu.
Do funkcji agregacji należą: Sum(), Count(), Min(), Max() i wiele innych.
Większości funkcji agregacji można używać zarówno w skrypcie ładowania danych, jak i w wyrażeniach wykresu, ale różnią się one składnią.
Używanie funkcji agregacji w skrypcie ładowania danych
Funkcji agregacji można używać wyłącznie wewnątrz instrukcji LOAD i SELECT.
Używanie funkcji agregacji w wyrażeniach wykresu
Parametr funkcji agregacji nie może zawierać innych funkcji agregacji, chyba że takie wewnętrzne agregacje zawierają kwalifikator TOTAL. Do bardziej zaawansowanych agregacji należy używać zaawansowanej funkcji Aggr w połączeniu z określonym wymiarem.
Funkcja agregacji wykonuje agregacje na zestawie możliwych rekordów zdefiniowanym przez selekcję. Można jednak zdefiniować alternatywny zestaw rekordów za pomocą wyrażenia set w analizie zestawów.
Analiza zestawów i wyrażenia zestawów
Jak obliczane są agregacje
Agregacja przetwarza w pętli rekordy określonej tabeli, agregując je. Na przykład Count(<Field>) policzy liczbę rekordów w tabeli, w której znajduje się <Field>. Jeśli chcesz agregować tylko odrębne wartości pól, musisz użyć klauzuli distinct, takiej jak Count(distinct<Field>).
Jeśli funkcja agregacji zawiera pola z różnych tabel, będzie przetwarzać w pętli rekordy iloczynu wektorowego tabel pól składowych. Powoduje to obniżenie wydajności i z tego powodu należy unikać takich agregacji, zwłaszcza gdy ma się duże ilości danych.
Agregacja pól klucza
W związku ze sposobem obliczania agregacji nie można agregować pól klucza, ponieważ nie jest jasne, której tabeli należy użyć do agregacji. Na przykład, jeśli pole <Key> łączy dwie tabele, nie jest jasne, czy Count(<Key>) ma zwrócić liczbę rekordów z pierwszej, czy z drugiej tabeli.
Jeśli jednak użyjesz klauzuli distinct, agregacja będzie dobrze zdefiniowana i można ją obliczyć.
W związku z tym, jeśli użyjesz pola klucza wewnątrz funkcji agregacji bez klauzuli distinct, QlikView zwróci liczbę, która może być bez znaczenia. Rozwiązaniem jest albo użycie klauzuli distinct, albo użycie kopii klucza, która znajduje się tylko w jednej tabeli.
Na przykład w poniższych tabelach ProductID jest kluczem między tabelami.
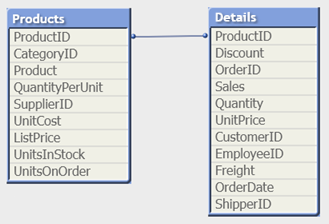
Count(ProductID) można liczyć w tabeli Products (która ma tylko jeden rekord na produkt — ProductID jest kluczem podstawowym) lub w tabeli Details (która najprawdopodobniej ma po kilka rekordów na produkt). Jeśli chcesz policzyć odrębne produkty, użyj Count(distinct ProductID). Jeśli chcesz policzyć liczbę wierszy w określonej tabeli, nie należy używać klucza.