
Семейство функций, известных как функции агрегирования, состоит из функций, для которых несколько значений поля являются вводимым значением и которые возвращают один результат на группу. В данных функциях группировка определяется измерением диаграммы или предложением group by в операторе скрипта.
В число функций агрегирования входят функции Sum(), Count(), Min(), Max() и многие другие.
Большинство функций агрегирования можно использовать как в скрипте загрузки данных, так и в выражениях диаграмм, но синтаксис имеет различия.
Использование функций агрегирования в скрипте загрузки данных
Функции агрегирования могут использоваться только внутри операторов LOAD и SELECT.
Использование функций агрегирования в выражениях диаграмм
Параметр функции агрегирования не должен содержать функции агрегирования, кроме внутреннего агрегирования, содержащего квалификатор TOTAL. Для получения более расширенных вложенных агрегирований необходимо использовать расширенную функцию Aggr вместе с заданным измерением.
Функция агрегирования агрегирует набор возможных записей, определенных выборкой. Однако альтернативное множество записей может быть определено выражением множества в анализе множеств.
Анализ множества и выражения множества
Порядок вычисления агрегирования
В ходе процедуры записи определенной таблицы циклически обрабатываются с целью агрегирования. Например, Count(<Field>) будет подсчитывать количество записей в таблице, где находится <Field>. Если требуется агрегировать только уникальные значения полей, необходимо использовать предложение distinct, например Count(distinct <Field>).
Если функция агрегирования содержит поля из разных таблиц, то она будет циклически обрабатывать записи перекрестной таблицы, включающей эти поля. Это приводит к снижению производительности, и по этой причине такого агрегирования следует избегать, особенно при больших объемах данных.
Агрегирование ключевых полей
В связи с порядком вычисления агрегирования невозможно агрегировать ключевые поля, так как не ясно, какую таблицу следует использовать для такого агрегирования. Например, если поле <Key> связывает две таблицы, становится неясно, какое количество записей должно быть возвращено Count(<Key>): в первой таблице или во второй.
Однако, если используется предложение distinct, агрегирование достаточно определено и может быть вычислено.
Поэтому если ключевое поле используется внутри функции агрегирования без предложения distinct, QlikView может вернуть количество, не имеющее смысла. Чтобы решить эту проблему, необходимо использовать либо предложение distinct, либо копию ключа, которая находится только в одной таблице.
Например, в следующих таблицах ProductID является ключом между таблицами.
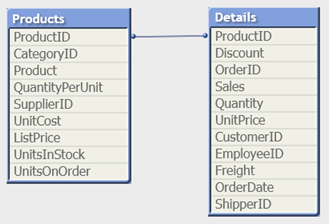
Count(ProductID) может подсчитываться в таблице Products (которая содержит всего по одной записи для каждого продукта, ProductID — это первичный ключ) либо в таблице Details (которая, скорей всего содержит по несколько записей для каждого продукта). Если требуется подсчитать количество уникальных продуктов, следует использовать Count(distinct ProductID). Если требуется подсчитать количество строк в конкретной таблице, не следует использовать ключ.