Traiter du langage naturel à l'aide du Studio Talend
Qu'est-ce que le traitement du langage naturel ?
-
la division d'un texte en termes individuels, qui sont des unités linguistiques basiques telles que des mots ou des signes de ponctuation,
-
la segmentation de phrases, qui consiste à segmenter les données d'entrée en phrases, en se basant sur les caractères marquant la fin d'une phrase tels que le point ou le point d'interrogation,
-
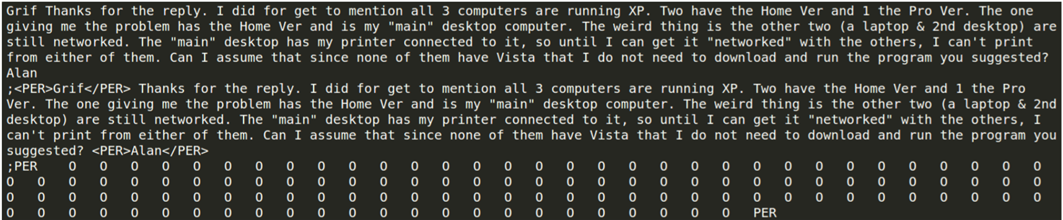
la reconnaissance d'entités nommées, qui consiste à rechercher et à classer des noms de personnes, des dates ainsi que des noms de lieux et d'organisations au sein d'un texte.
-
extraire des noms de personnes ou d'entreprises à partir de ressources textuelles,
-
regrouper des discussions autour d'un même sujet sur un forum,
-
trouver des discussions où certaines personnes sont nommées sans que ces personnes n'y participent,
-
établir un lien entre des entités.
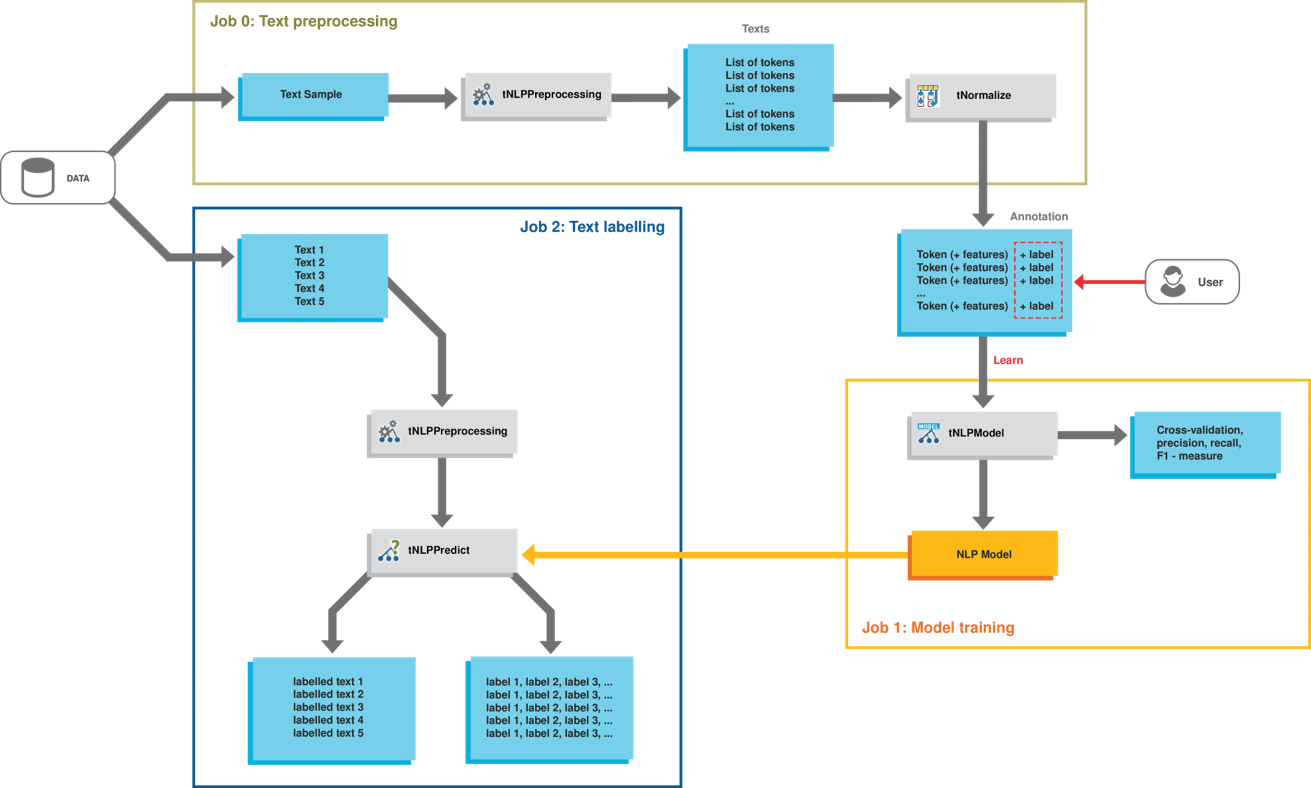
Workflow
-
le premier Job comprend les composants tNLPPreprocessing et tNormalize,
-
le second Job comprend un tNLPModel.
La seconde phase est implémentée dans un troisième Job comprenant un tNLPPredict.
-
divise un échantillon de texte en termes individuels,
-
nettoie l'échantillon de texte en supprimant toutes les balises HTML.
Ensuite, le tNormalize convertit les termes individuels au format CoNLL.
-
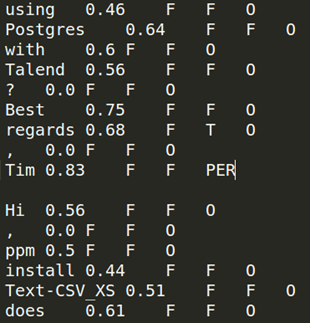
crée des caractéristiques pour chaque terme individuel,
-
apprend un modèle de classification.
Le tNLPPredict libelle automatiquement les données textuelles à l'aide du modèle de classification généré par le tNLPModel.