
東アジアパターン頻度インジケーター
東アジアパターン頻度インジケーターには東アジアパターン頻度と東アジアパターン低頻度が含まれます。
| インジケーター | 目的 |
|---|---|
| 東アジアパターン頻度 | 個別のパターンごとに最も頻度の高いレコードの数を計算します。 |
| 東アジアパターン低頻度 | 個別のパターンごとに頻度の低いレコードの数を計算します。 |
上記の2つのインジケーターにはLatin文字のみ使用できます。また、Javaエンジンでのみ使用できます。アジア系のデータのパターンを特定する時に有用です。
上記の2つのインジケーターは、アジア系の文字を下記のテーブルで説明するルールに従ってH,K,CやGなどの文字に変換することでパターンを生成します。
| 文字タイプ | 使用方法 |
|---|---|
| ラテン数字 | すべてのASCII数字が9に置き換わります |
| Latin小文字 | すべてのASCII Latin文字がaに置き換わります |
| Latin大文字 | すべての大文字のLatin文字がAに置き換わります |
| 全角ラテン数字 | すべてのASCII数字が9に置き換わります |
| 全角Latin小文字 | すべてのASCII Latin文字がaに置き換わります |
| 全角Latin大文字 | すべての大文字のLatin文字がAに置き換わります |
| ひらがな | すべてのひらがな文字がHに置き換わります |
| 半角カタカナ | すべての半角カタカナ文字がkに置き換わります |
| 全角カタカナ | すべての全角カタカナ文字がKに置き換わります |
| 片仮名 | すべてのカタカナ文字がKに置き換わります |
| 漢字 | 漢字がCに置き換わります |
| ハングル | ハングル文字がGに置き換わります |
カラム分析でサポートされるアジア系の文字タイプと関連するUnicode範囲については、ドキュメンテーションをご覧ください。
以下は、[East Asia Pattern Frequency] (東アジアパターン頻度)インジケーターおよび[East Asia Pattern Low Frequency] (東アジアパターン低頻度)インジケーターを[address] (住所)カラムに使用したカラム分析の例です。
[East Asia Pattern Low Frequency] (東アジアパターン低頻度)インジケーターの分析結果は次のようになります。
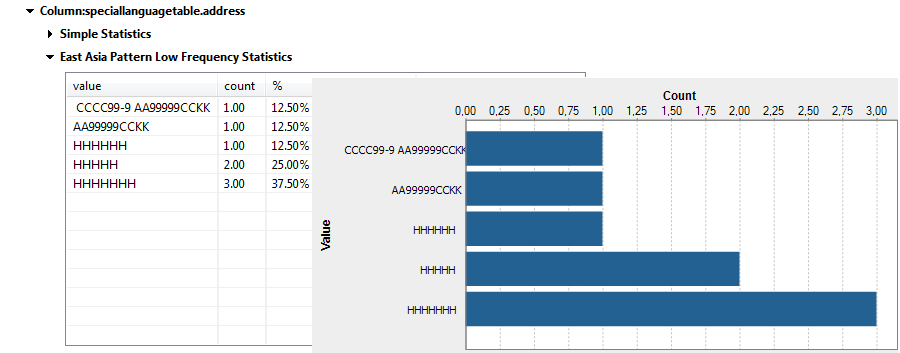
これらの結果には、個別のパターンごとに最も頻度の低いレコードの数が示されます。文字と数字によるパターンもあれば、文字だけのパターンもあります。パターンは長さも異なります。すなわち、住所は一貫しておらず、訂正とクリーン化が必要になる場合があります。
どのデータベースでも選択できるインジケーターを次のテーブルに示します。
| データ型 | 数字 | Text | Date | その他 | ||||
|---|---|---|---|---|---|---|---|---|
| 分析エンジンのタイプ | Java | SQL | Java | SQL | Java | SQL | Java | SQL |
| 東アジアパターン頻度 |

|

|
|
|
|
|
|
|
| 東アジアパターン低頻度 |
|
|
|
|
|
|
|
|