
ジョブを変換
標準からSparkへといったように、ジョブを別のフレームワークからの変換によって作成できます。
ソースジョブで使用しているコンポーネントをターゲットジョブにも使用できる場合は、このオプションをお勧めします。たとえば、標準ジョブをSpark Batchジョブに変換する必要があるとします。
手順
-
ジョブの説明を変更する必要がある場合は、該当するフィールドを変更します。
変更不可能なフィールドの情報を編集する必要がある場合は、[Project settings] (プロジェクト設定)ウィザードを使って変更を行う必要があります。詳細は、プロジェクト設定のカスタマイズをご覧ください。
例
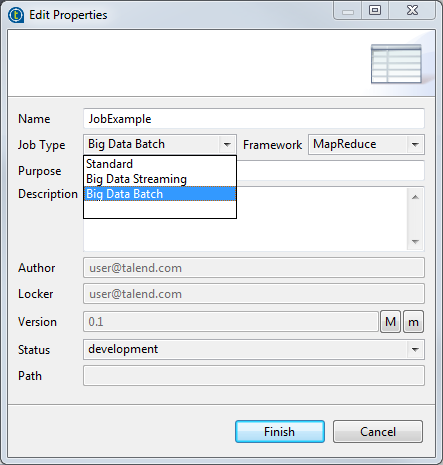
タスクの結果
変換済みのジョブが[Big Data Batch] (ビッグデータバッチ)ノードの下に表示されます。
コンテキストメニューから[Duplicate] (重複)オプションを選択して変換にアクセスすることも可能です。このアプローチを使うと、ソースジョブを元のフレームワークと共に保持する一方で、重複ジョブをターゲットフレームワークに作成できます。
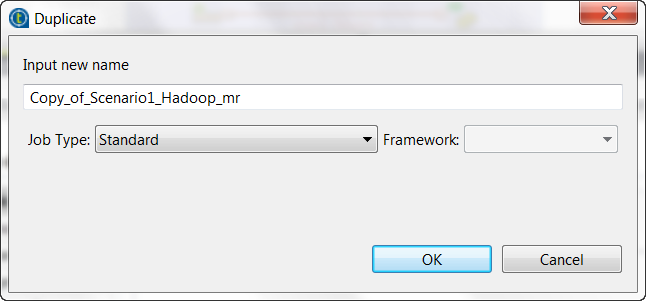
MapReduceジョブからこの手順を繰り返し、標準ジョブまたは別のフレームワークに変換することもできます。その場合は、コンテキストメニューから[Edit Big Data Batch properties] (ビッグデータバッチプロパティの編集)を選択します。
標準ジョブで、リポジトリーで定義したHadoopへの接続を使用している場合は、[Finish] (終了)ボタンをクリックすると[Select node] (ノードの選択)ウィザードが表示され、その接続を選択してMapReduceジョブで自動的にその接続を再利用できます。
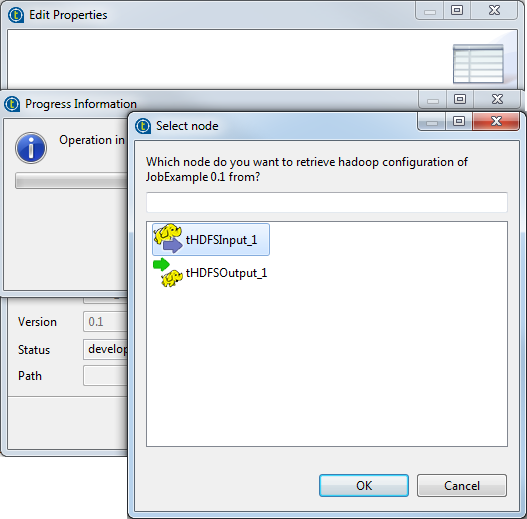
このウィザードに表示されるコンポーネントは、ソースの標準ジョブで使用されているものです。それを選択すると、作成しているMapReduceジョブでもHadoopの接続メタデータが再利用されます。