
Azure ADLS Gen1に出力を書き込む
予想される映画データとリジェクトされた映画データをAzure ADLS Gen1フォルダーの別々のディレクトリーに書き込むよう、2つの出力コンポーネントが設定されます。
始める前に
- DatabricksのSparkクラスターが正しく作成され、実行されていることを確認します。詳細は、Azureドキュメンテーションの[Create Databricks workspace] (Databricksワークスペースの作成) (英語のみ)を参照してください。
-
Azure Data Lake Storage Gen1システムへのアクセスに使用する認証情報に関するSparkプロパティが各行に追加されていることをご確認ください。
spark.hadoop.dfs.adls.oauth2.access.token.provider.type ClientCredential spark.hadoop.dfs.adls.oauth2.client.id <your_app_id> spark.hadoop.dfs.adls.oauth2.credential <your_authentication_key> spark.hadoop.dfs.adls.oauth2.refresh.url https://login.microsoftonline.com/<your_app_TENANT-ID>/oauth2/token - Azureアカウントを持っています。
- 使用するAzure Blob Storageサービスが適切に作成されました。Azure Active Directorディレクトリーに、それにアクセスするための適切な権限があります。この件はAzureシステムの管理者に問い合わせて確認するか、Moving data from ADLS Gen1 to ADLS Gen2 using Azure Databricksで、「Granting the application to be used the access to your ADLS Gen1 folder」(使用するアプリケーションにADLS Gen1フォルダーへのアクセスを付与)というセクションの説明に従ってください。
手順
-
tAzureFSConfigurationをダブルクリックして、その[Component] (コンポーネント) ビューを開きます。
例
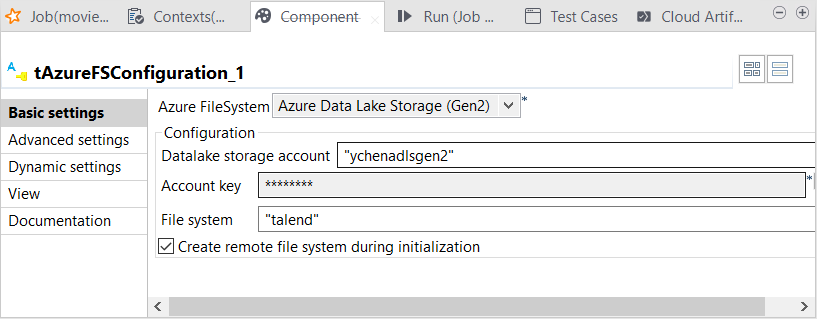
-
out1リンクを受け取るtFileOutputParquetコンポーネントをダブルクリックします。
[Basic settings] (基本設定)ビューがStudioの下側に開きます。
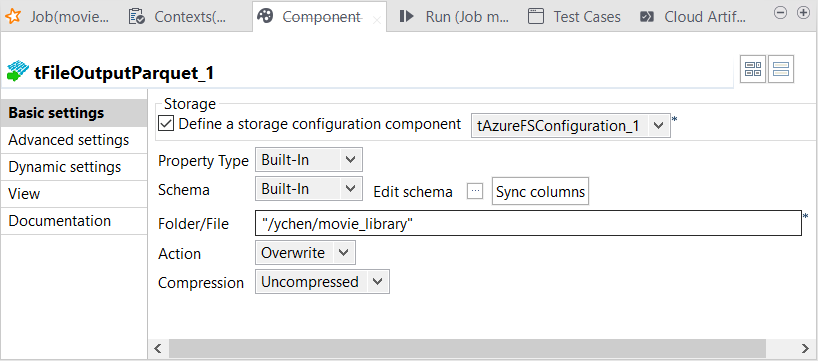
-
[Run] (実行)ビューで[Spark configuration] (Spark設定)タブをクリックしてビューを開きます。
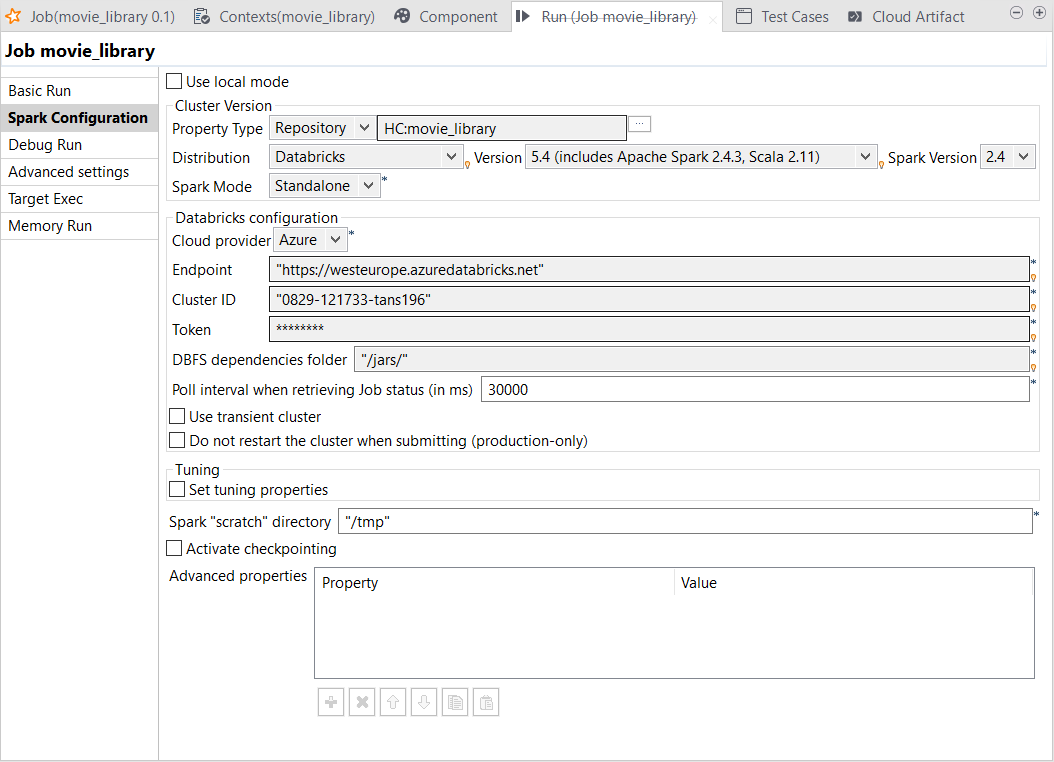
タスクの結果
[Run] (実行)ビューがStudioの下側に自動的に開きます。
完了すると、たとえばMicrosoft Azure Storage Explorerで、出力がADLS Gen1フォルダーに書き込まれていることを確認できます。