
ビッグデータ
| 機能 | 説明 |
|---|---|
| Spark BatchのtIcebergTableという新しいコンポーネント | Talend StudioのSpark BatchジョブでtIcebergTableコンポーネントが利用可能になりました。 tIcebergTableを使用すれば、次のようなさまざまなアクションを実行できます:
情報メモ注: ブランチングとタグ付けはSparkフレームワークのIceberg 1.3.0でのみサポートされており、ローカルモードのSpark Universal 3.0ではサポートされていません。Icebergバージョンの詳細は、ベンダー側でご確認ください。
![Spark BatchジョブでのtIcebergTableの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/release-notes/8.0/Content/Resources/images/ticebergtable-sparkbatch.png) |
| Spark Universal 3.3.xでHDInsight 5.1をサポート | Spark Universal 3.3.xを使い、HDInsightでSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。この設定は、Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードでADLS Gen2ストレージまたはAzureストレージを使って実行できます。 このモードを選択すると、Talend StudioはHDInsight 5.1バージョンと互換性を持つようになります。 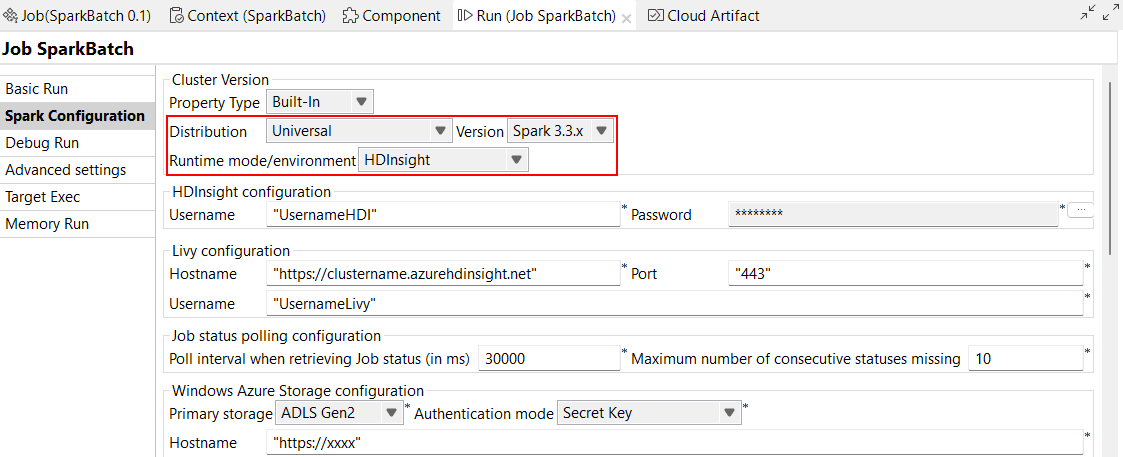
|