
パターンを使用した値のフィルタリング
プロファイリングエリアの[Pattern] (パターン)タブには、データを構成する文字のタイプと数がグラフィカルに表現されています。
言い換えると、単語または文字の精度によってレコードがどう構造化されているかを視覚的に確認できます。データにフィルターをすばやく簡単に適用する方法にもなります。
カラムのコンテンツを選択する時に、横棒チャートには使用されているさまざまなパターンの配分が表示されます。選択するデータのタイプに応じて、表示されるデフォルトパターンは異なります。
- カラムタイプがtextまたはbooleanの場合は単語ベース
- カラムタイプがdateまたはnumberの場合は文字ベース
ただし、データのタイプに関係なく、[Pattern] (パターン)タブで文字ベースと単語ベースの間でパターンを切り替えることができます。
たとえばファーストネームとラストネームにおけるデータクオリティの問題を検出するのに、単語ベースのパターン分析は効率的な手法です。句読点や数字が含まれているなど、単語のみで構成されていない名前は、目立つのですぐに判明します。他方、文字ベースのパターンは、クライアントIDやアカウント番号などの構造化されたデータの場合により適しています。文字や数字の数が正しくない場合は、チャートでわかります。
このサンプルでは、名前、メール、会社名、サブスクリプションの日付など、標準的な顧客情報のデータセットを使用します。

手順
-
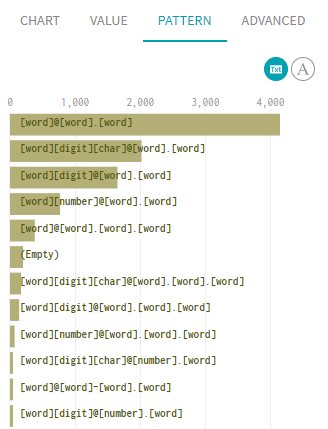
プロファイリングエリアの[Pattern] (パターン)タブをクリックします。
このカラムに使用されているさまざまなパターンが、チャート形式で表示されます。このカラムではtextデータが使用されるため、チャートには、単語ベースのパターンを使用したデータ配分が表示されます。
-
[A]アイコンをクリックして文字ベースのビューに切り替えます。
これにより、別の視点からデータを分析できます。

-
[Ctrl]ボタンを押したまま、[word][number]@[word].[word]パターンに対応するバーをクリックして、このフィルターを前のフィルターに追加します。
グリッドには、これらの2つのフィルターに合うデータだけが表示されます。
