
行の重複除去
[Remove duplicate rows] (重複行を削除)ファンクションを使用すると、完全に重複しているすべての行を簡単に削除し、データセットに1行のみを保持できます。
情報メモ注: このファンクションはSparkジョブ、およびHDFSやS3のエクスポートとは互換性がありません。
たとえば、コピーアンドペーストの失敗などのヒューマンエラー、さらには自動操作のためにスプレッドシートの情報が重複することがあります。この例では、受信したデータセットには、顧客情報がすべてシステムで複製された行が含まれています。
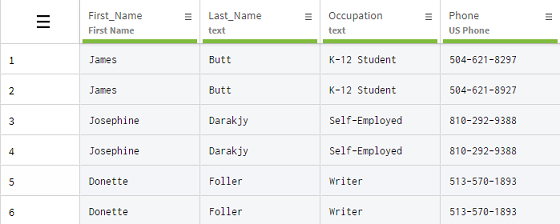
[Remove duplicate rows] (重複行を削除)を使用すると、データセットを簡単に消去できます。
手順
-
[Remove duplicate rows] (重複行を削除)機能にカーソルを置いて結果を表示し、クリックして適用します。
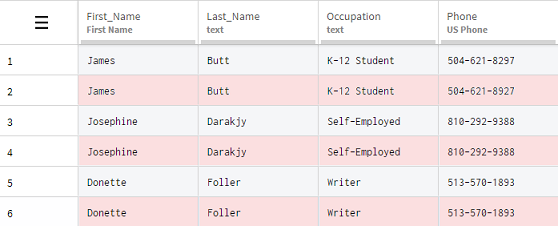
タスクの結果
重複した情報はすべて1回の簡単な操作で削除でき、データセットでは各行1行のみが表示されるようになります。