
Deduplicating rows
You can use the Remove duplicate rows function to easily delete all the rows that are exact duplicates and keep only one in your dataset.
Information noteNote: This
function is not compatible with Spark Jobs, and HDFS or S3 exports.
Duplicated information can be introduced in spreadsheets because of human error, like a bad copy and paste for example, as well as automated operations. In this example, you received a dataset containing customer information, where all the rows are systematically duplicated.
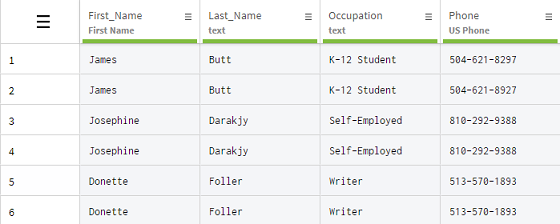
You will use the Remove duplicate rows to easily clean your dataset.
Procedure
-
Point your mouse over the Remove duplicate rows function
to preview its result, and click to apply it.
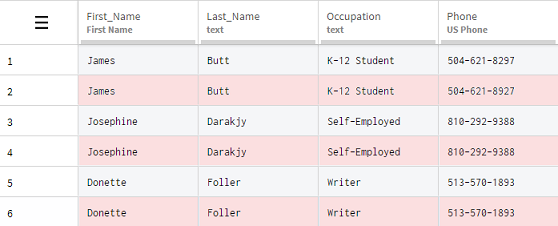
Results
All the duplicated information has been removed in one simple action, leaving you with only one correct occurrence of each row in your dataset.