ビッグデータバッチジョブを作成
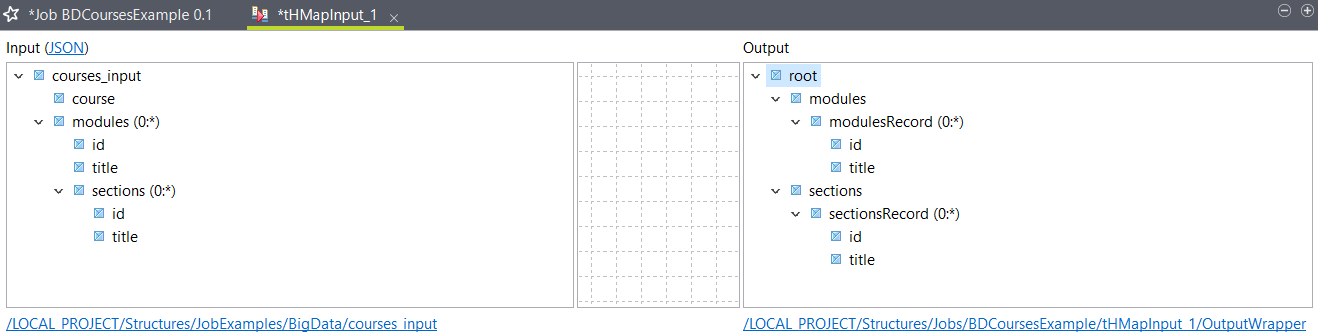
tHMapInputと2つの出力コンポーネントを持つジョブを作成し、JSONファイルを2つのCSVファイルに変換します。
このタスクについて
この例では入力にローカルファイルを使用していますが、HDFS接続を作成することもできます。詳細は、HDFSコンポーネント (英語のみ)をご覧ください。
手順
-
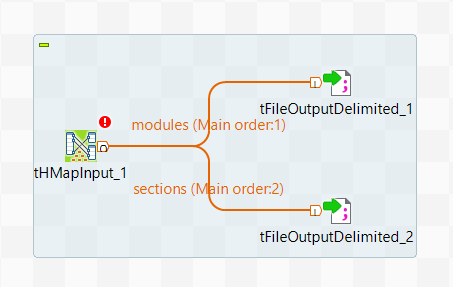
で、modulesとsectionsという名前の接続でtHMapInputを2つのtFIleOutputDelimitedコンポーネントにリンクさせ、ターゲットコンポーネントからスキーマを取得するかどうか尋ねられた場合は[Yes] (はい)をクリックします。
ジョブは次のようになります。
-
tHMapInputジョブをダブルクリックし、ウィザードに従ってマップを生成します。
- オプション:
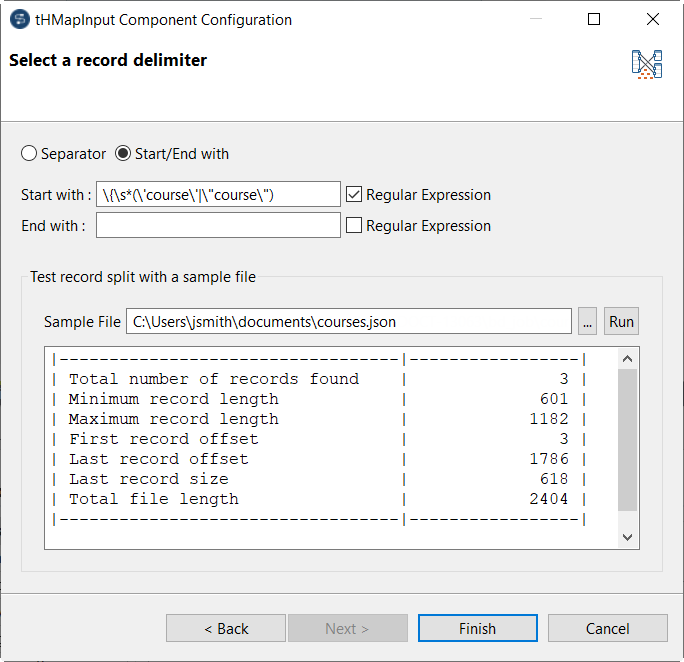
[...]ボタンをクリックしてサンプル入力ファイルを追加し、[Run] (実行)をクリックして見つかったレコードをチェックします。
この場合、見つかるレコードは3つです。
例
- オプション:
[...]ボタンをクリックしてサンプル入力ファイルを追加し、[Run] (実行)をクリックして見つかったレコードをチェックします。
タスクの結果