
親ジョブを設定
手順
-
[Contexts] (コンテキスト)ビューでは以下のようにします:
-
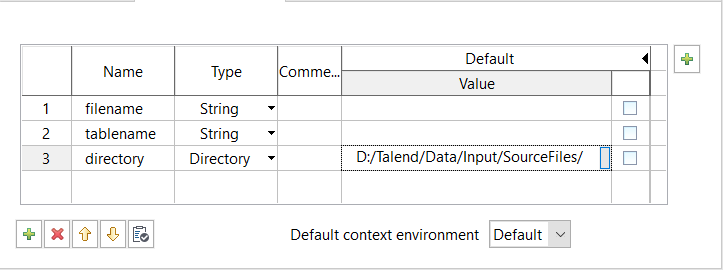
変数ディレクトリーの[Value] (値)フィールドをクリックして、[directory] (ディレクトリー)を指定します。表示される小さなボタンをクリックして、ソースファイルが保存されているディレクトリーを参照します。
-
変数ディレクトリーの[Value] (値)フィールドをクリックして、[directory] (ディレクトリー)を指定します。表示される小さなボタンをクリックして、ソースファイルが保存されているディレクトリーを参照します。
-
tMapコンポーネントをダブルクリックして、マップエディターを開き、マップエディターで以下のようにします:
-
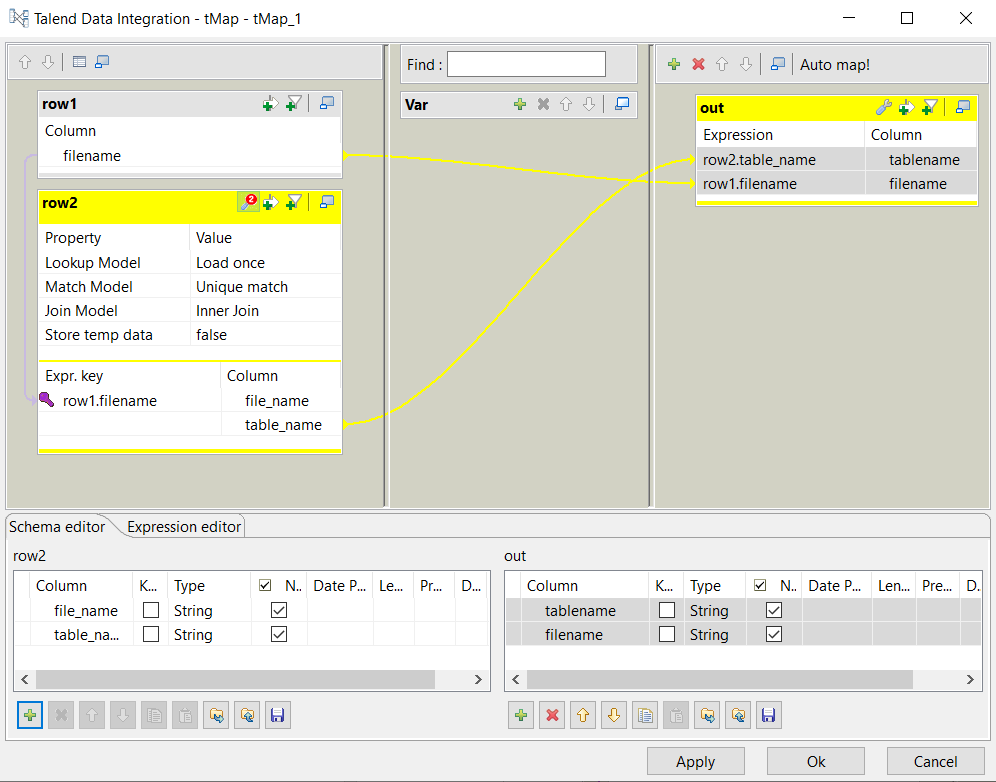
テーブル row2のtable_nameカラムをドラッグして、、テーブルoutのtablenameカラムにドロップします。
-
テーブル row2のtable_nameカラムをドラッグして、、テーブルoutのtablenameカラムにドロップします。