
Creating a connection to HCatalog
Procedure
-
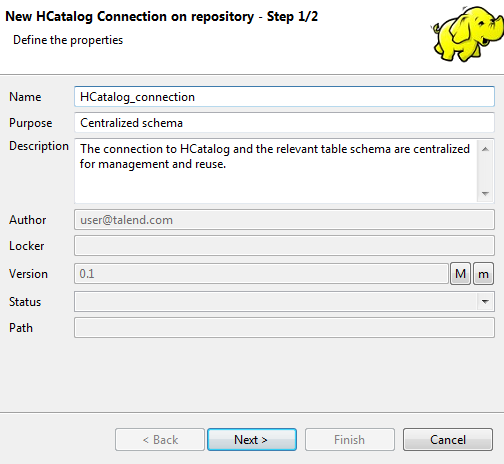
In the connection wizard that opens up, fill in the generic properties of the
connection you need create, such as Name,
Purpose and Description. The Status field
is a customized field you can define in File > Edit
project properties.
-
Click Next when completed. The second step
requires you to fill in the HCatalog connection data. Among the properties,
Host name is automatically pre-filled with
the value inherited from the Hadoop connection you selected in the previous
steps. The Templeton Port and the Database are using the default values.
This database is actually a Hive database and Templeton (WebHcat) is used as a REST-like web API by HCatalog to issue commands. For further information about Templeton (WebHcat), see Apache documentation.
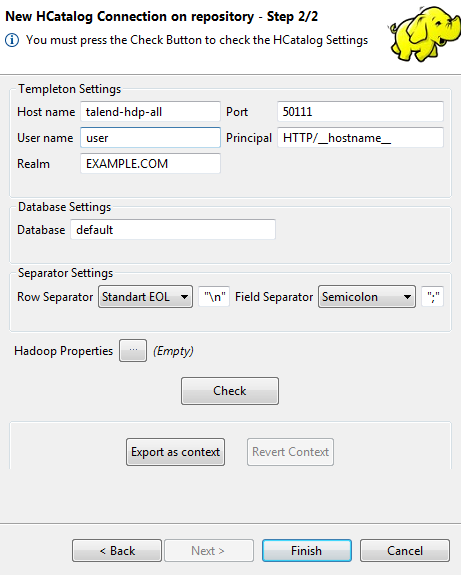 The Principal and the Realm fields are displayed only when the Hadoop connection you are using enables the Kerberos security. They are the properties required by Kerberos to authenticate the HCatalog client and the HCatalog server to each other.Information noteNote:
The Principal and the Realm fields are displayed only when the Hadoop connection you are using enables the Kerberos security. They are the properties required by Kerberos to authenticate the HCatalog client and the HCatalog server to each other.Information noteNote:In order to make the host name of the Hadoop server recognizable by the client and the host computers, you have to establish an IP address/hostname mapping entry for that host name in the related hosts files of the client and the host computers. For example, the host name of the Hadoop server is talend-all-hdp, and its IP address is 192.168.x.x, then the mapping entry reads 192.168.x.x talend-all-hdp. For the Windows system, you need to add the entry to the file C:\WINDOWS\system32\drivers\etc\hosts (assuming Windows is installed on drive C). For the Linux system, you need to add the entry to the file /etc/hosts.
-
Click Finish to validate these
changes.
The created HCatalog connection is available under the Hadoop cluster node in the Repository tree view.
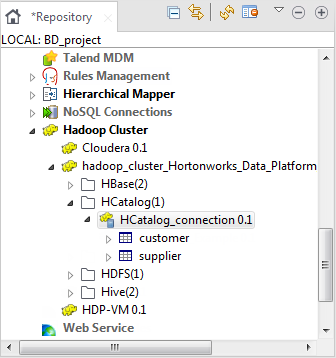 Information noteNote: This Repository view may vary depending on the edition of Talend Studio you are using.If you need to use an environmental context to define the parameters of this connection, click the Export as context button to open the corresponding wizard and make the choice from the following options:
Information noteNote: This Repository view may vary depending on the edition of Talend Studio you are using.If you need to use an environmental context to define the parameters of this connection, click the Export as context button to open the corresponding wizard and make the choice from the following options:-
Create a new repository context: create this environmental context out of the current Hadoop connection, that is to say, the parameters to be set in the wizard are taken as context variables with the values you have given to these parameters.
-
Reuse an existing repository context: use the variables of a given environmental context to configure the current connection.
For a step-by-step example about how to use this Export as context feature, see Exporting metadata as context and reusing context parameters to set up a connection.
-