
Analyze the log file and save the result
Procedure
-
In the Basic settings view of the
tPigFilterRow component, click the
[+] button to add a line in the
Filter configuration table, and set
filter parameters to remove records that contain the code of 404 and
pass the rest records on to the output flow:
- In the Logical field, select AND.
- In the Column field, select the code column of the schema.
- Select the NOT check box.
- In the Operator field, select equal.
- In the Value field, enter 404.

-
In the Basic settings view of the
tPigFilterColumns component, click
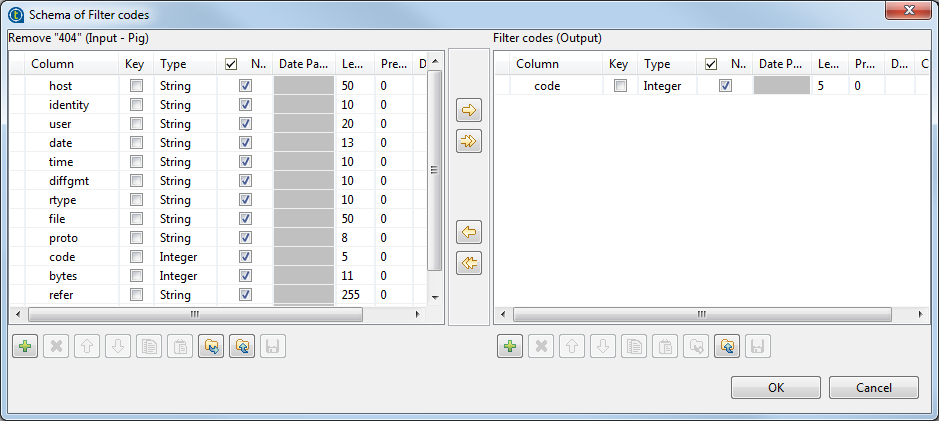
the [...] button to open the Schema dialog box. Select the column
code in the Input panel and click the single-arrow button to copy
the column to the Output panel to pass
the information of the code column to
the output flow. Click OK to confirm
the output schema settings and close the dialog box.
-
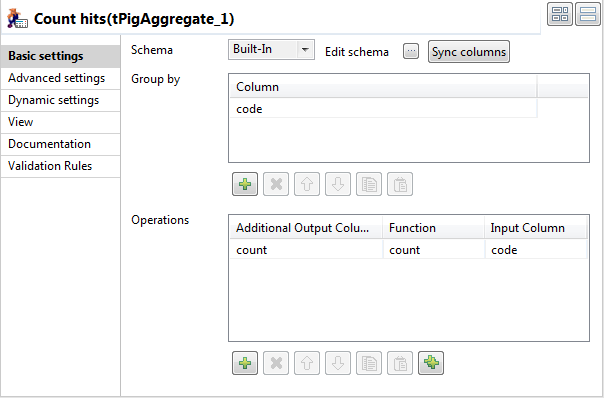
Configure the following parameters to count the number of occurrences
of each code:
- In the Group by area, click the [+] button to add a line in the table, and select the column count in the Column field.
- In the Operations area, click the [+] button to add a line in the table, and select the column count in the Additional Output Column field, select count in the Function field, and select the column code in the Input Column field.
-
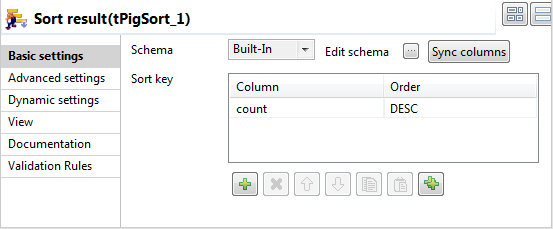
In the Basic settings view of the
tPigSort component, configure the
sorting parameters to sort the data to be passed on:
- Click the [+] button to add a line in the Sort key table.
- In the Column field, select count to set the column count as the key.
- In the Order field, select DESC to sort data in the descendent order.
-
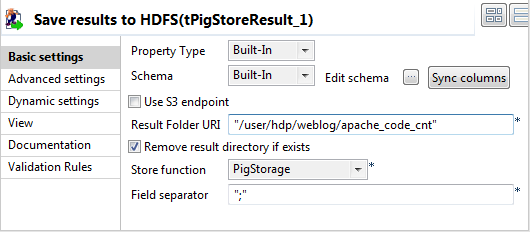
In the Basic settings view of the
tPigStoreResult component,
configure the component properties to upload the result data to the
specified location on the Hadoop system:
- Click Sync columns to retrieve the schema from the preceding component.
- In the Result file URI field, enter the path to the result file, /user/hdp/weblog/apache_code_cnt in this example.
- From the Store function list, select PigStorage.
- If needed, select the Remove result directory if exists check box.
-
In this step, we will configure the fifth Job, E_Pig_Count_IPs, to analyze the uploaded access log file using a
similar Pig chain as in the previous Job to get the IP addresses of successful
service calls and their number of visits to the website. We can use the component settings in the previous Job, with the following
differences:
-
In the Schema dialog box of the
tPigFilterColumns component, copy
the column host, instead of code, from the Input panel to the Output panel.

-
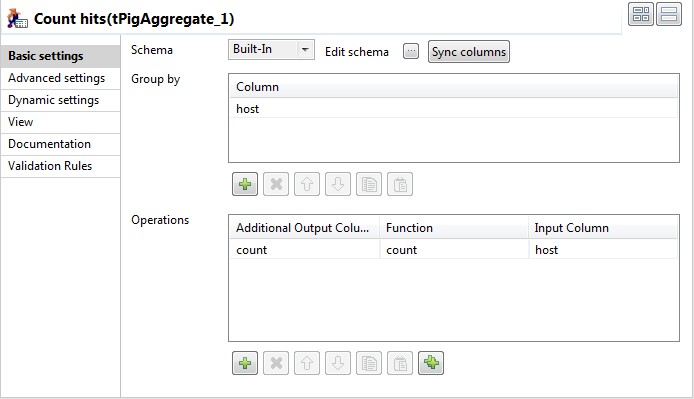
In the tPigAggregate component,
select the column host in the
Column field of the Group by table and in the Input Column field of the Operations table.
-
In the Schema dialog box of the
tPigFilterColumns component, copy
the column host, instead of code, from the Input panel to the Output panel.