
One-way data synchronization
One-way sync is from a source A to a destination B. Potential challenges and points of attention:
Incremental processing
For performance reasons, retrieve data incrementally from the source as opposed to getting all data from the source on each run.
Use a block list data incrementally
for this:
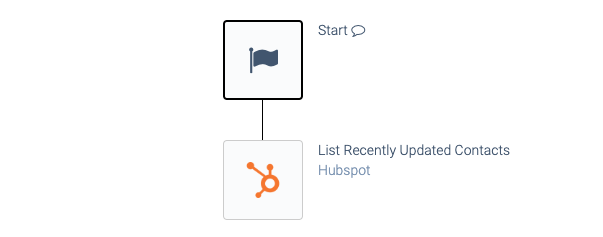
Listing data incrementally.
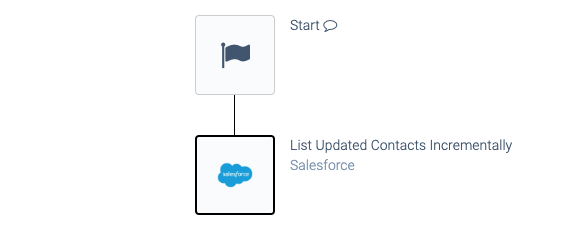
Most incremental blocks will return both newly created and updated objects. Make sure to test this.
If such a block is not available (because it is not supported in a specific connector), you can potentially use a block with a moving window
instead. This block will e.g. get all records that are new or updated in the last 24 hours. Example:
Listing data incrementally with a moving window.
Avoid duplicates - use Upserts
Avoid creating duplicates in the destination. Use Upserts (insert or update) to avoid duplicates.
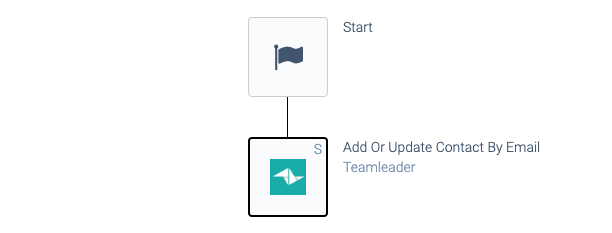
Some connectors have Snippets
(smart blocks) that perform an Upsert. Example:
an automation with an upsert snippet.
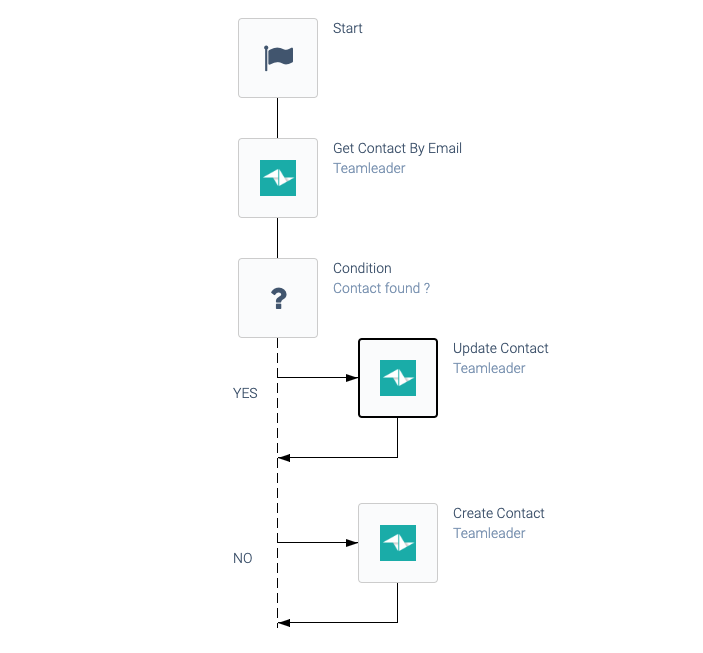
If an Upsert snippet is not available, implement this pattern in your Blend:
An upsert automation pattern.
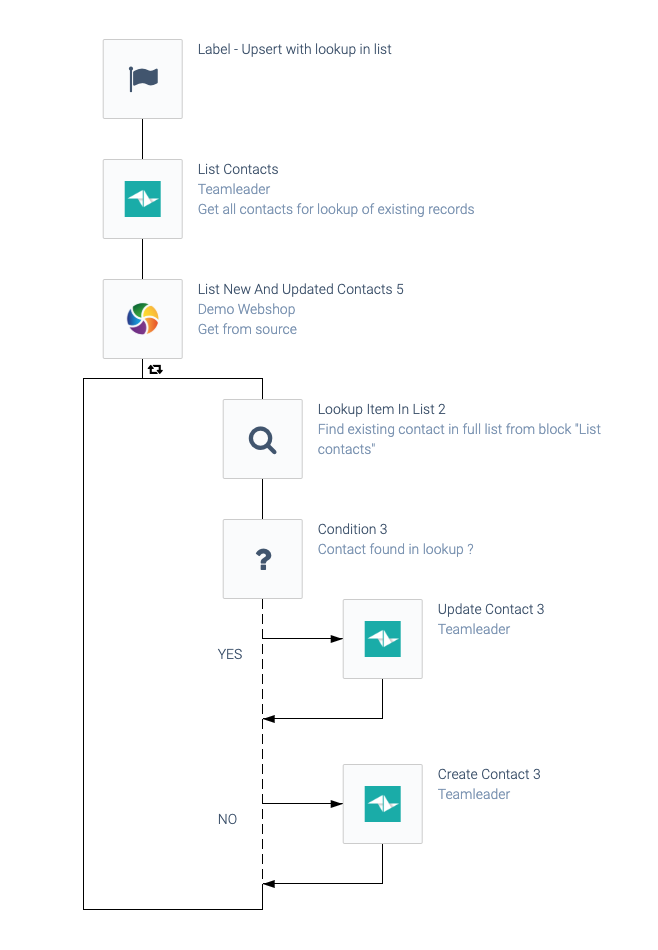
Here's an alternative Upsert pattern, that will do a lookup from a list of all records, to check for existing records. This can be useful when it's impossible to check for one existing object (e.g. you are syncing companies and the feature find company by VAT number
does not exist):
An alternative upsert automation pattern.
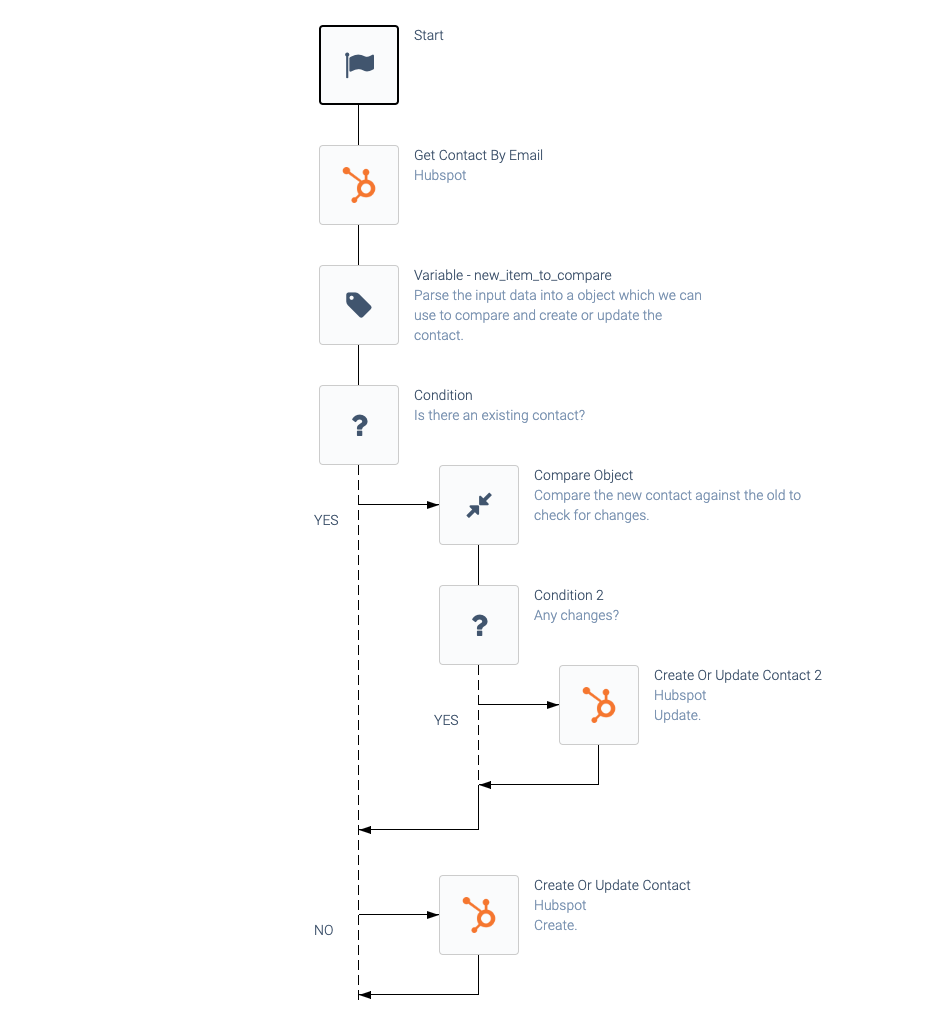
Only update when needed
Do not update objects in the destination when not needed. Even when using Upserts, you should not update an object in the destination when no changes are needed, to avoid changing the timestamp last update
of the object. Example:
Avoiding unnecessary updates.
Missing fields in update cause field to be emptied
Make sure that fields which are not included in your update do not cause these fields to be emptied in the object that is updated.
Matching objects
Choose a unique key to match objects between A and B, e.g. email address
for Contacts, or name + date
for Projects.
If the key is not unique in one of the platforms, store the id of A in the object in B as an external id
and use this for matching. An example is Contacts where email addresses are unique in A but not in B.
If transformations are needed on keys, make sure to perform these transformations rigorously everywhere, e.g. also in a Compare object
block when checking if an update is needed. A good example is phone numbers, that may be formatted differently in A and B. Also be careful with spaces (make sure to trim
keys) and with keys that may be truncated in the destination because of limited key length (e.g. when using a combined key name + date + location
for an Order).
Relationships between objects
Make sure to create parent objects first before creating child objects (e.g. Customers and Orders). When child objects are created or updated in a separate automation (which is e.g. triggered from a Webhook), make sure to add logic to look up the parent object and add the link (foreign key), and add logic to create the parent object if it does not exist yet.
Synchronize deletes
When an object is deleted in A, it may also need to be deleted in B.
It's hard to detect which data was deleted in A because most API's do not expose this information. Some platforms have a Webhook available on delete
.
Another solution is to build a Compare automation and delete in B what is missing in A. This is a risk, if a mistake is made in the Compare Blend, you may end up deleting data in B mistakenly. For example, you should not delete data in B that is missing in A, when the data in B does not originate from A. This risk can be eliminated by writing an external id
from A in objects in B (see paragraph matching objects
).
Exactly once processing
Sometimes you need to make sure that data from the source is processed only once and never sent to the destination more than once, in order to avoid creating duplicates in the destination.
This could be needed if an Upsert is impossible to do, e.g. because you cannot lookup existing records in the destination or because data in the destination is altered by another process or by users, which makes a lookup useless.
By using an incremental block such as List new and updated contacts incrementally
, you are - in theory - certain that each record from the source is only processed once. But if you reset the pointer (and do a full run again) or if you use a combination of a scheduled automation and webhooks, you may process the same record from the source multiple times.
In this case, the pattern exactly once processing
can be used. This pattern uses the Qlik Application Automation for OEM Data Store as an intermediate database to keep track of which records from the source were already processed.
Read more about the Qlik Application Automation for OEM Data Store
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!