
Normalisation de données à l'aide de composants Map/Reduce
Ce scénario s'applique uniquement aux solutions Talend avec Big Data.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
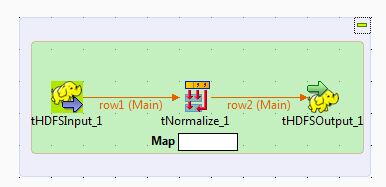
Vous pouvez créer la version Map/Reduce du Job décrit précédemment à l'aide des composants Map/Reduce. Ce Job Map/Reduce Talend génère du code Map/Reduce et s'exécute de manière native dans Hadoop.
Notez que les composants Map/Reduce de Talend ne sont disponibles que pour les utilisateurs et utilisatrices ayants souscrit à une offre Big Data et que ce scénario ne peut être reproduit qu'avec des composants Map/Reduce.
Les données d'exemple utilisées dans ce scénario sont les mêmes que celles utilisées dans le Job décrit précédemment.
ldap,
db2, jdbc driver,
grid computing, talend architecture ,
content, environment,,
tmap,,
eclipse,
database,java,postgresql,
tmap,
database,java,sybase,
deployment,,
repository,
database,informix,javaÉtant donné que le Studio Talend vous permet de convertir un Job Map/Reduce en Job Standard (non Map/Reduce), et vice-versa, vous pouvez convertir le scénario expliqué plus tôt afin de créer ce Job Map/Reduce. Ainsi, la plupart des composants utilisés peuvent garder leurs paramètres d'origine afin de réduire votre charge de travail pour la création de ce Job.
Avant de commencer à reproduire ce scénario, assurez-vous d'avoir les droits d'accès appropriés à la distribution Hadoop à utiliser. Procédez comme suit :