Clouderaでコンテキスト変数を使用
このシナリオでは、異なるClouderaオンプレミスランタイム(7.1.7 Spark 3.2.xと7.1.9 Spark 3.3.x)の間でSparkジョブを実行する場所を選択します。
これは、オンプレミス(7.1.x)とクラウド(7.2.x)のClouderaディストリビューションが混在している場合も該当します。
この機能は、Talend Studioコンテキスト変数機能とQlik Spark Universal 3.3.xディストリビューションモード(Clouderaディストリビューションの最新モード)で有効になります。
始める前に
- お使いのターゲットディストリビューションがSpark 2、Spark 3、またはその両方と同時に互換性を持つかどうかについては、Clouderaのドキュメンテーション (英語のみ)でご確認ください。
- Cloudera Managerから、使用する各Hadoopサービス(HDFS、Hive、HBaseなど)のクライアント設定をダウンロードします。詳細は、ClouderaのドキュメンテーションでDownloading Client Configuration Files (英語のみ)をご覧ください。
Hadoopクラスターへのメタデータ接続を作成
手順
-
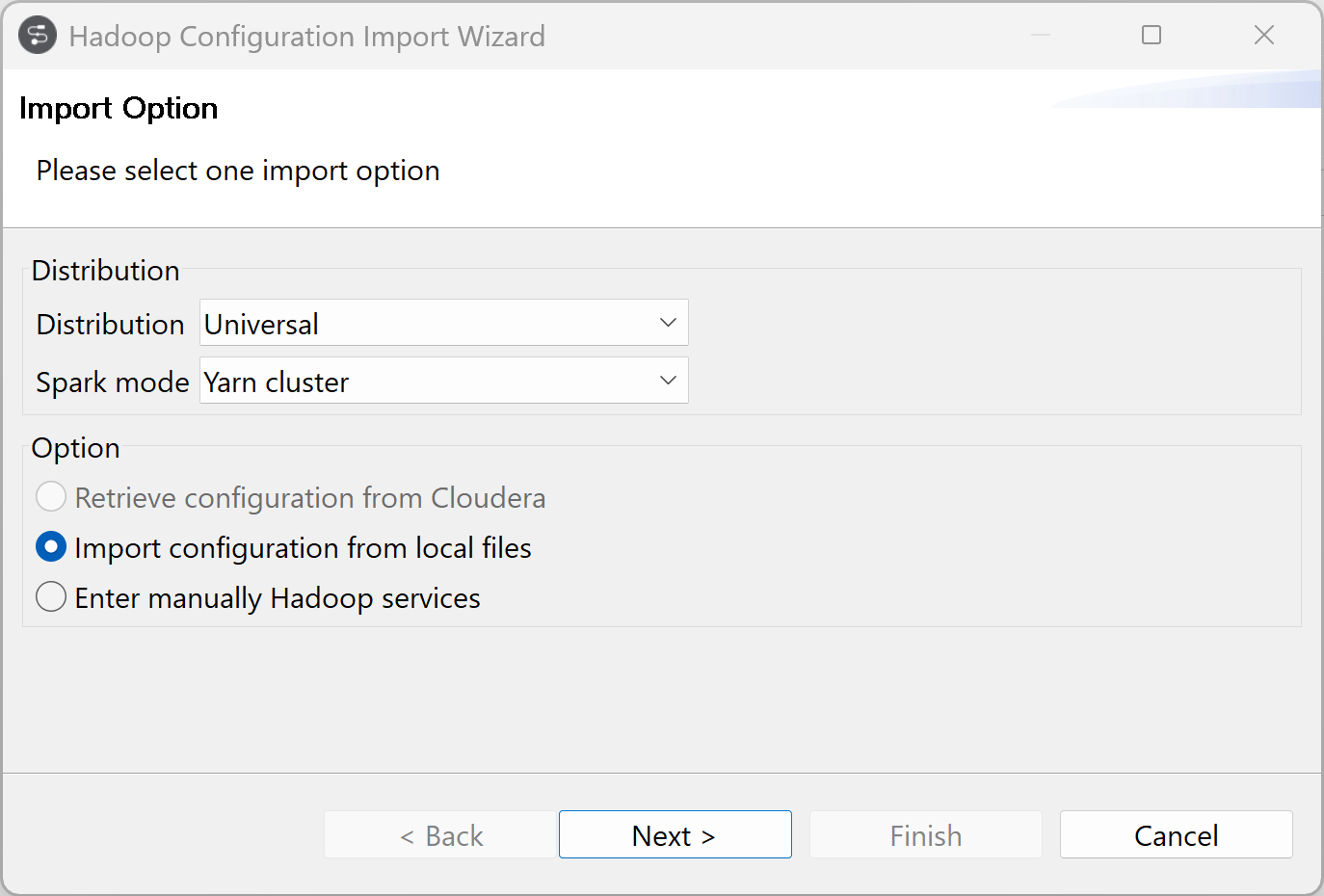
ディストリビューションを選択(この例ではUniversal)し、Sparkモードを選択(この例ではYarn cluster)します。
Hadoop設定をインポート
手順
-
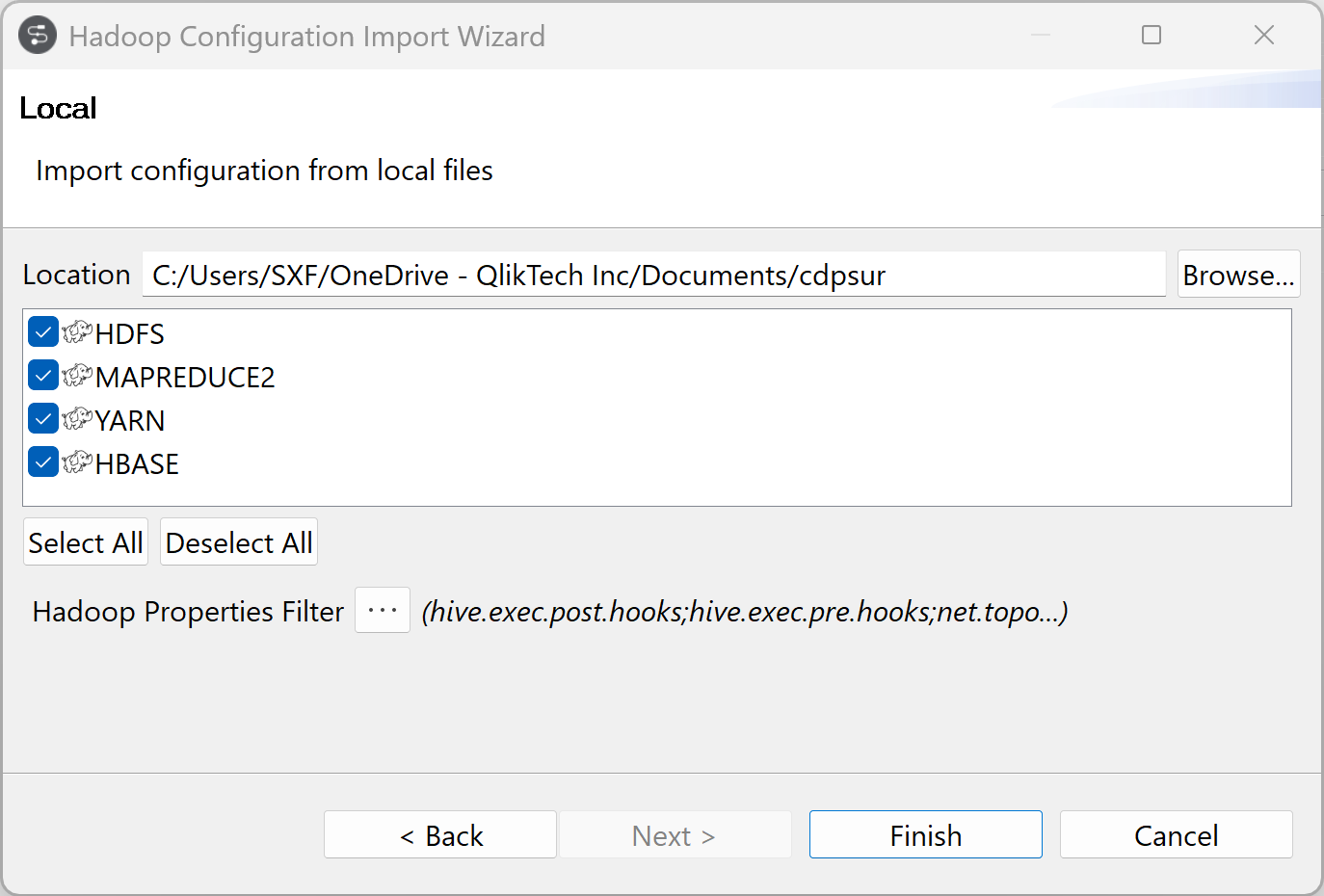
クライアント設定の場所を指定し、[Finish] (終了)をクリックします。
-
[Update connection parameters] (接続パラメーターをアップデート)タブには、デフォルトのパラメーターが既に入力されています。
ただし、必要に応じて次のいずれかの操作を実行できます:
- [Use a key tab to authenticate] (キータブを使って認証)を選択し、Hadoopクラスターで認証する。
- [Use custom classpath] (カスタムクラスパスを使用)を選択し、実行するClouderaクラスパスを定義する。この場合は、Spark 2ライブラリーかSpark 3ライブラリーを指定します。
![[Update connection parameters] (接続パラメーターをアップデート)タブ。](/talend/ja-JP/studio-user-guide/8.0-R2025-08/Content/Resources/images/update-connection-parameters.png)
メタデータ接続をコンテキスト依存化
コンテキスト値を使えば、1つのクラスターを異なるパラメーターで使用できます。
手順
-
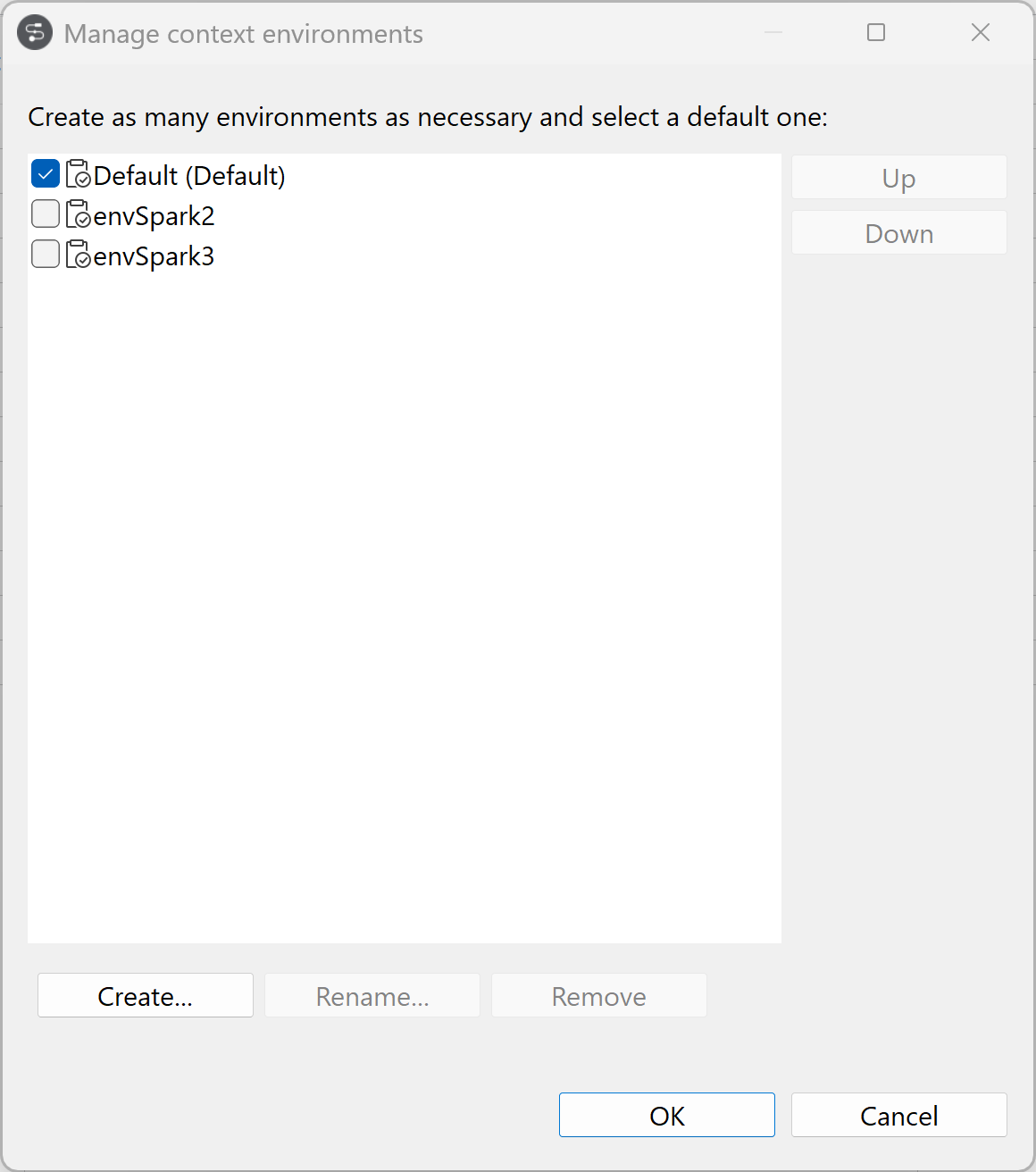
[Manage environments] (環境を管理)をクリックし、環境を必要な個数だけ作成して、デフォルトの環境を選択します。
この例では、[Create] (作成)をクリックしてSpark 2とSpark 3の環境を追加します。