
一部のデータベースについて必要な知識
Google BigQuery
Google BigQueryからのデータをプロファイリングするには、JDBC接続の設定を行う必要があります。
詳細は、接続URL (英語のみ)をビルドする方法をご覧ください。
RECORDデータ型はサポートされていません。
JDBC接続を設定する時は、zipファイルから抽出した各jarファイルを指定します。
Hive
- Hiveサーバーの設定に移動します。
- HiveServer2 Java Heap Sizeパラメーターを1GB以上に設定します。
Hiveデータベースへの接続を選択した場合、他のデータベースタイプのようにさまざまな分析を作成して実行できます。
接続ウィザードで、[Distribution] (ディストリビューション)からHiveをホストするプラットフォームを選択する必要があります。また、Hiveのバージョンとモデルも設定する必要があります。
For more information, see Apache Hadoop documentation (英語のみ).
Hive接続の組み込みモードでユーザー名を変更する場合は、接続を使用するプロファイリング分析を正しく実行できるよう、Talend Studioを再起動する必要があります。
- [Hadoop Properties] (Hadoopのプロパティ)の横のボタンをクリックし、開いたダイアログボックスで[+]ボタンをクリックし、テーブルに2つの行を追加します。
- パラメーター名にmapred.job.map.memory.mbおよびmapred.job.reduce.memory.mbを入力します。
- それらの値をデフォルト値の1000に設定します。
通常、この値は計算を実行するために適切です。
| サポート対象外のインジケーター | サポート対象外の機能 | サポート対象外の分析 |
|---|---|---|
| SQLエンジンを使った場合: Soundex低頻度 パターン(低)頻度 上位クオータイルおよび下位クオータイル 中央 すべての日付頻度インジケーター |
|
Hiveに対応していない唯一の分析は、[Time Correlation Analysis] (時間コリレーション分析)です。これはHiveにはDateデータ型がないためです。この分析タイプの詳細は、時間コリレーション分析をご覧ください。 |
Hiveの場合、分析結果での右クリックオプション(ジョブを生成してデータを検証、標準化、重複除去)はどれもサポートされていません。これらのジョブの詳細は、データを検証をご覧ください。
HiveおよびHBase
さまざまな分析を作成して実行できるようHiveまたはHBaseへの接続を選択した場合、前述のように、[Distribution] (ディストリビューション)からHiveまたはHBaseをホストするプラットフォームを接続ウィザードで選択する必要があります。
- パラメーター: yarn.application.classpath
- 値は次のとおりです。 /etc/hadoop/conf,/usr/lib/hadoop/,/usr/lib/hadoop/lib/,/usr/lib/hadoop-hdfs/,/usr/lib/hadoop-hdfs/lib/,/usr/lib/hadoop-yarn/,/usr/lib/hadoop-yarn/lib/,/usr/lib/hadoop-mapreduce/,/usr/lib/hadoop-mapreduce/lib/
Microsoft SQL Server
Microsoft SQL Server 2012以降がサポートされています。
Windows認証モードでMicrosoft SQL Serverデータベースに接続する場合は、[Db Version] (Dbバージョン)リストから[Microsoft]または[JTDS open source] (JTDSオープンソース)を選択します。
Microsoft SQL Serverデータベースを使ってレポート結果を保存する場合、サポート対象となるドライバーはMicrosoft JDBCとJTDSオープンソースです。
レポートと分析結果を保存するためにAzure SQLデータベースへの接続を作成するには、データベース接続設定の[Additional parameters] (追加パラメーター)フィールドにssl=requireと入力します。
- JTDSのウェブサイト (英語のみ)から、JTDSドライバーバージョン1.3.1をダウンロードします。
- アーカイブからファイルを抽出し、オペレーティングシステムに応じてntlmauth.dllファイルをx64/SSOまたはx86/SSOの下からコピーします。
- ntlmauth.dllファイルを%SYSTEMROOT%/system32に貼り付けます。
次のエラーが発生した場合: SSOが失敗しました: ネイティブSSPIライブラリーがロードされませんでした。Talend Studioによって使用されているJREのbinディレクトリーにntlmauth.dllを貼り付けます。
Microsoft SQL Serverデータベースでは、大文字小文字を区別しない照合を使用してください。そうでないと、レポートの生成に失敗することがあります。java.sql.SQLException: Invalid column name 'rep_runtime'のようなエラーが発生するおそれがあります。照合順序に関する詳細は、Windows Collation Name (英語のみ)をご覧ください。
ntextデータ型はサポートされていません。
MySQL
JDBCを使用してMySQLへの接続を作成する場合、データベース名をJDBC URLに含めることは必須ではありません。[JDBC URL]フィールドで指定したデータベース接続URLにデータベース名が含まれているかどうかに関係なく、データベースがすべて取得されます。
たとえば、jdbc:mysql://192.168.33.41:3306/tbi?noDatetimeStringSync=true (tbiはデータベース名)、またはjdbc:mysql://192.168.33.41:3306/?noDatetimeStringSync=trueを指定した場合、すべててのデータベースが取得されます。
データおよびメタデータ内の代理ペアをサポートするには、MySQLサーバー設定ファイルの以下のプロパティを編集する必要があります。
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
character-set-server=utf8mb4Netezza
Netezzaデータベースでは正規表現はサポートされません。このデータベースで正規表現を使用する場合は、次のいずれかを実行する必要があります。
- NetezzaシステムにSQL Extensions Toolkitパッケージをインストールします。IBM Netezza SQL Extensions toolkit installation and setup (英語のみ)にある説明に従って、このツールキットで提供されているregex_likeファンクションをSQLテンプレートで使用します。
- Talend Studioのの下のPattern MatchingディレクトリーにNetezzaのインジケーター定義を追加します。
Netezzaに対して定義する必要のあるクエリーテンプレートは、SELECT COUNT(CASE WHEN REGEXP_LIKE(<%=COLUMN_NAMES%>,<%=PATTERN_EXPR%>) THEN 1 END), COUNT FROM <%=TABLE_NAME%><%=WHERE_CLAUSE%>です。
Oracle
代理ペアをサポートするには、データベースのNLS_CHARACTERSETパラメーターをUTF8またはAL32UTF8に設定する必要があります。
デフォルトのNLS_CHARACTERSETパラメーターは次のとおりです。
- NLS_CHARACTERSET=WE8ISO8859P15
- NLS_NCHAR_CHARACTERSET=AL16UTF16
Oracle Custom
[DB Type] (データベースタイプ)としてOracle Customを使ってOracleデータベースに接続するためには、[Use SSL Encryption] (SSL暗号化を使用)チェックボックスと[Need Client authentication] (クライアント認証が必要)チェックボックスをオンにし、[Trust Store Path] (TrustStoreのパス)フィールドと[Trust Store Password] (Trust Storeのパスワード) フィールドに入力します。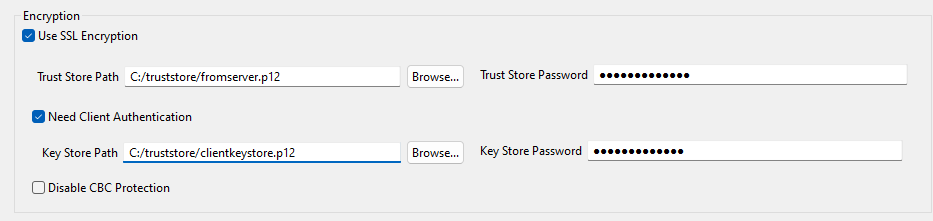
PostgreSQL
JDBC接続経由でPostgreSQLデータベースに接続すると、INT4データ型とINT8データ型がStringデータ型に置換されます。その結果、分析でT-Swooshアルゴリズムを使用している場合はサバイバーシップファンクションが数字ではなく文字列に適用されます。
- 分析を閉じ、Integrationパースペクティブに切り替えます。
- [Metadata] (メタデータ)を展開し、データベース接続を右クリックしてと進みます。
- アップデートするテーブルのチェックボックスをオンにします。
- [Creation status] (作成ステータス)を[Success] (成功)に設定して[Next] (次へ)をクリックします。
- データベース型がないカラムがInteger型でなければならない場合は、[DB Type] (データベース型)をINTに設定します。
- [Finish] (終了)をクリックしてダイアログボックスを閉じます。
- Profilingパースペクティブに切り替えて分析を開きます。
- [Survivorship Rules for Columns] (カラムのサバイバーシップルール)で、アップデートしたカラムをいったん削除して追加し直します。サバイバーシップファンクションが数字用(最大数および最小数)になったことがわかります。
SAP HANA
SAP HANAからのデータのプロファイリングは、テーブル、ビュー、計算ビューの各スキーマでのみ可能です。
Soundex頻度統計インジケーターは英語のアルファベットのみサポートしています。
Snowflake
Snowflakeからのデータをプロファイリングする場合はJDBC接続が必要です。
テーブル名とストラクチャーが同じ場合は、コンテキストを切り替えることでデータベースやスキーマも切り替えられます。カタログやスキーマの切り替えはJDBC URLに基づいて行われます。コンテキストを切り替えた後は、接続ノードの下に表示されるのはURLのカタログまたはスキーマのみです。
詳細は、Configuring the JDBC Driver (英語のみ)をご覧ください。
Integrationパースペクティブ内のSnowflakeノードの下に作成した接続は使用できません。
Teradata
Teradataデータベースへの接続を選択した場合、[Use SQL Mode] (SQLモードを使用)の横の[Yes] (はい)オプションを選択し、Talend Studioでのメタデータの取得にSQLクエリーを使用できるようにします。JDBCドライバーはパフォーマンス不良となる可能性があるため、このデータベースでは推奨されません。
Teradataデータベースでは、正規表現ファンクションは、バージョン14からのみデフォルトでインストールされます。このデータベースの以前のバージョンで正規表現を使用する場合、Teradataにユーザー定義ファンクションをインストールし、Talend StudioにTeradataのインジケーター定義を追加します。