
TalendジョブがApache Sparkで動作するしくみ
Talend Sparkジョブは、以下のいずれのモードでも実行できます:
-
ローカル: Talend Studioは実行時にSpark環境自体をビルドし、Talend Studio内でジョブをローカルに実行します。このモードでは、ローカルマシンの各プロセッサーがSparkワーカーとして使用されて計算を行います。この設定ビューに設定するパラメーターは最小限しか必要とされません。
このローカルマシンは、ジョブが実際に実行されるマシンです。
-
[Standalone] (スタンドアロン): Talend StudioはSpark対応のクラスターに接続し、このクラスターからジョブを実行します。
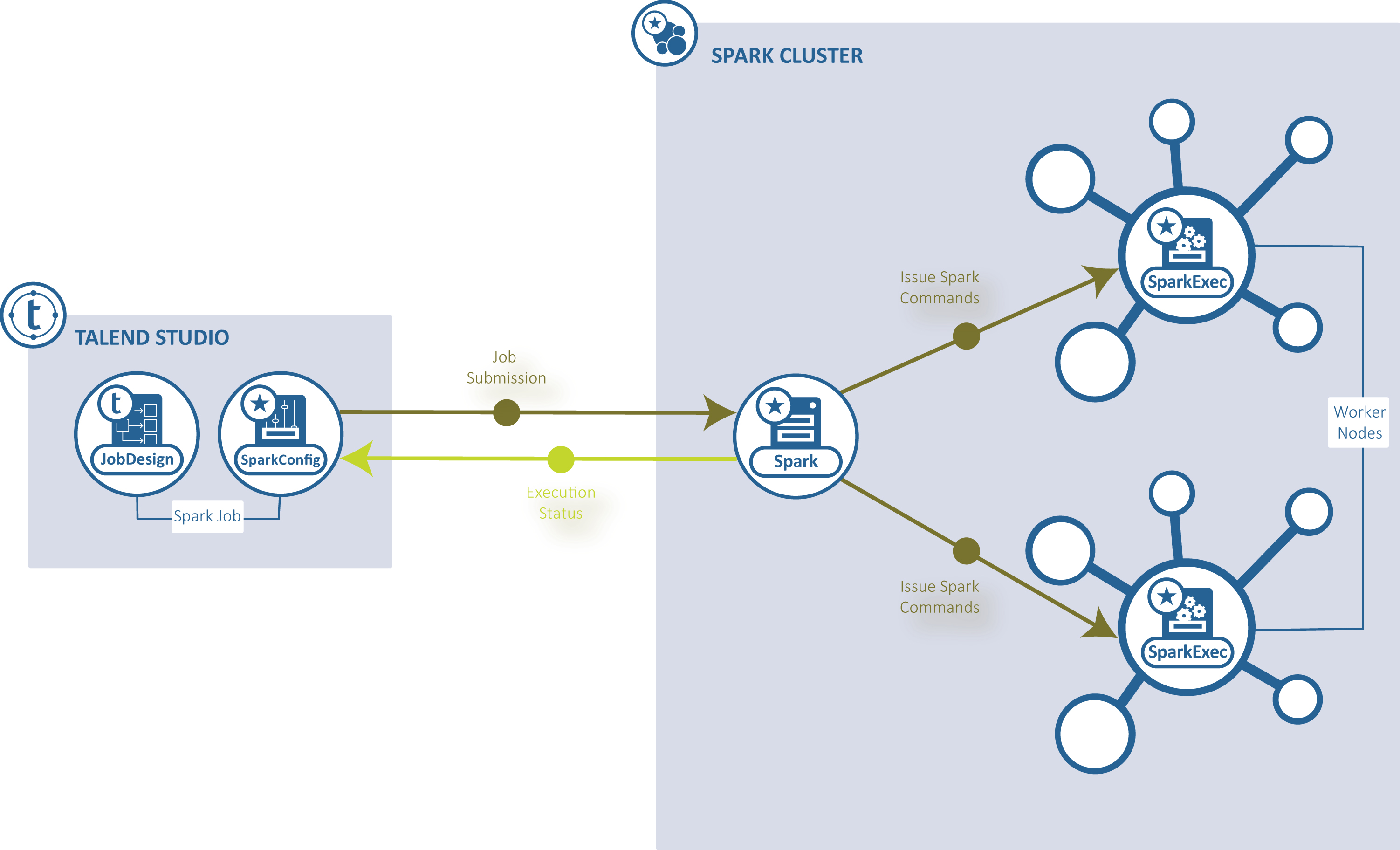
-
[YARN client] (YARNクライアント): Talend StudioはSparkドライバーを実行してジョブの実行方法をオーケストレーション化し、特定のHadoopクラスターのYARNサービスにそのオーケストレーション化を送信して、そのYARNサービスのリソースマネージャーが適宜実行リソースを要求できるようにします。
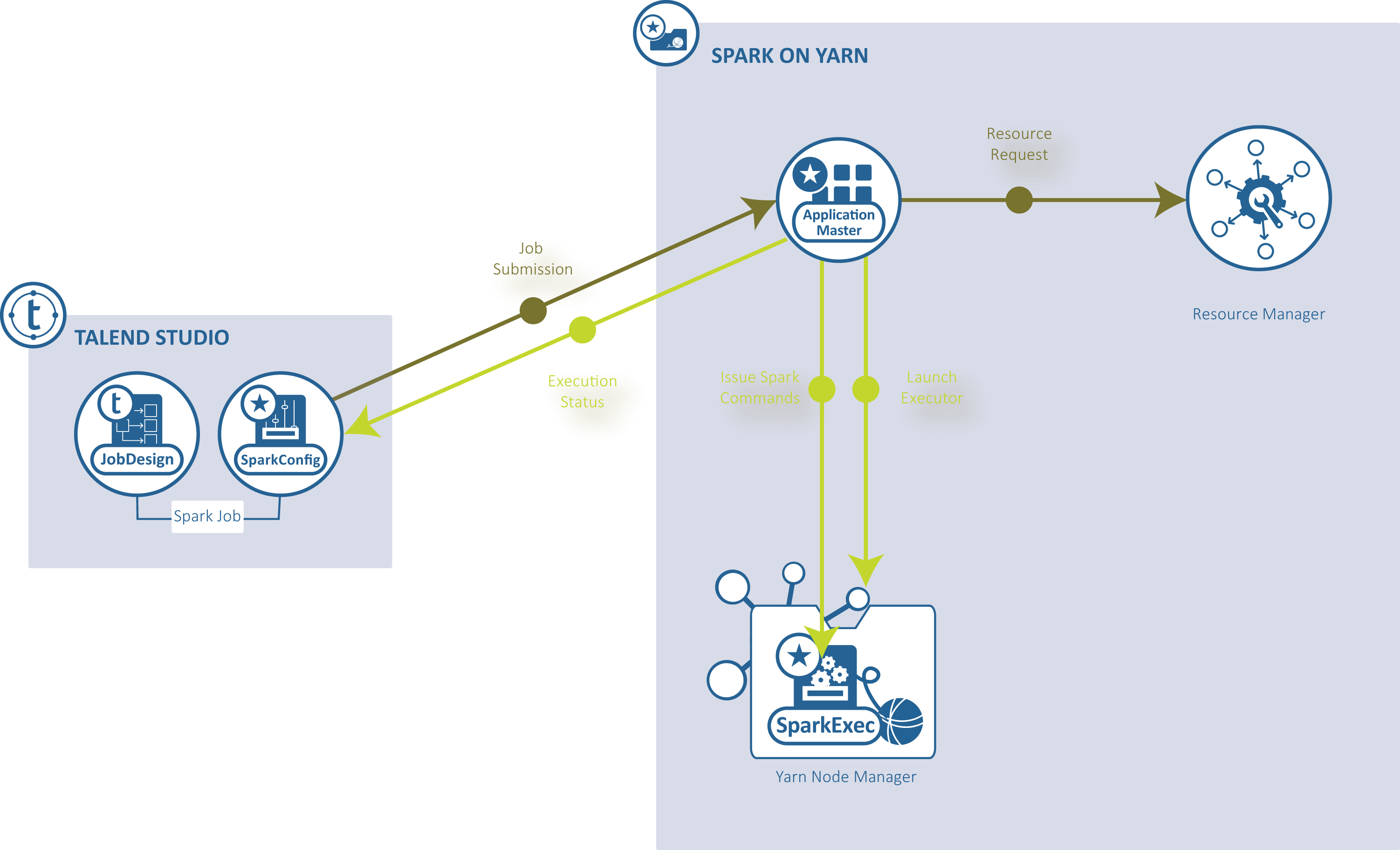
-
[YARN cluster] (YARNクラスター): Talend Studioはジョブを送信し、YARNおよびApplicationMasterからジョブの実行情報を収集します。Sparkドライバーがクラスター上で実行され、Talend Studioから独立して実行できます。
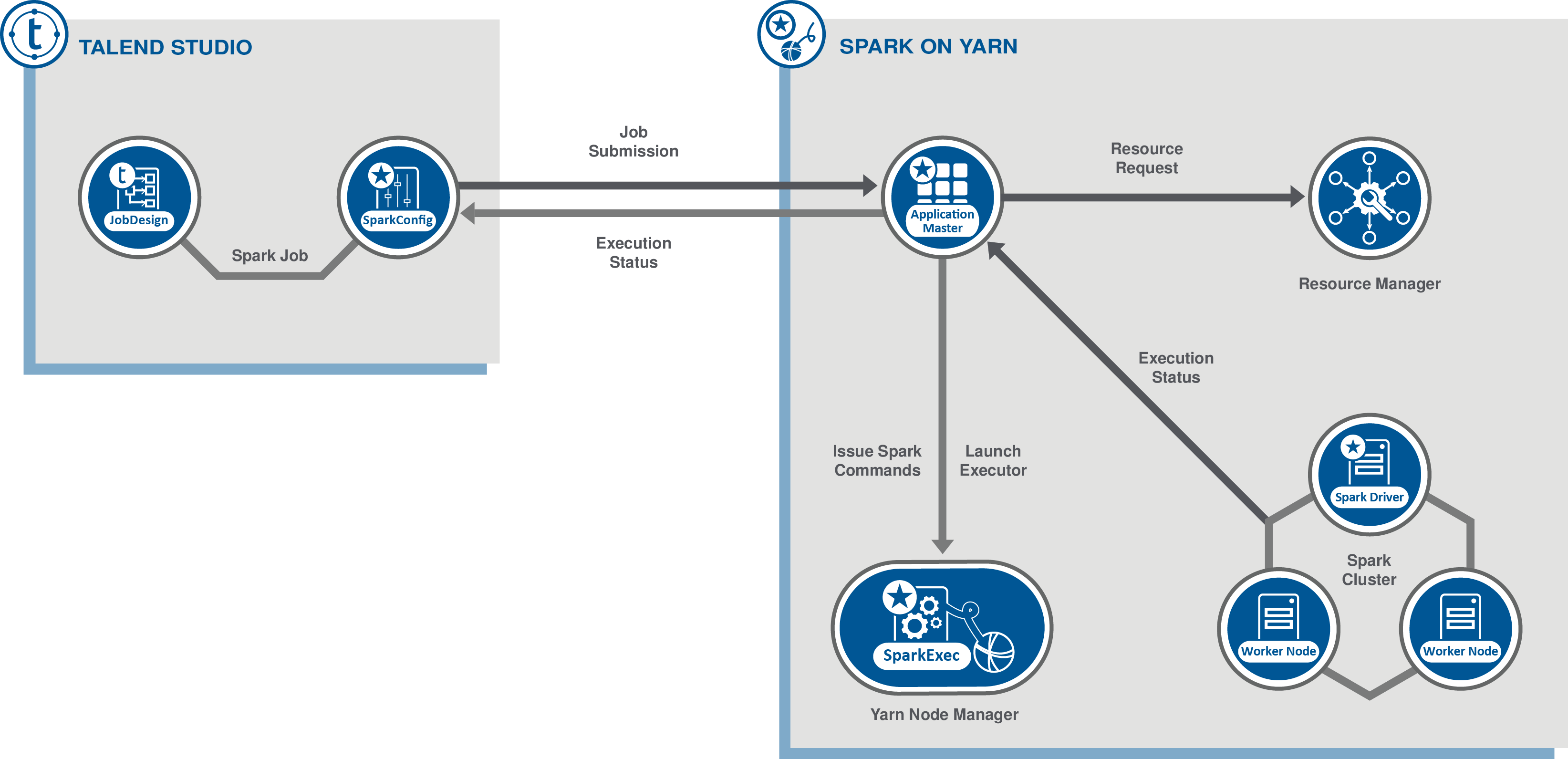
Talend StudioでSparkジョブをデザインする時は、専用のSparkコンポーネントを使ってクラスターへの接続を設定します。実行時には、この設定でTalend Studioはクラスターと直接通信して以下のオペレーションを行うことができます。
-
Sparkジョブを[Standalone] (スタンドアロン)モードのマスターサーバー、または使用しているクラスターの[Yarn client] (Yarnクライアント)モードまたは[Yarn cluster] (Yarnクラスター)のApplicationMasterサーバーに送信する
-
関連するジョブリソースを同じクラスターの分散ファイルシステムにコピーする。クラスターはその後、残りの実行を完了します。これには、ジョブの初期化、ジョブIDの生成、実行の進行情報と結果のTalend Studioへの送信があります。
Talend Sparkジョブは、ApacheからのSparkドキュメンテーションで説明されているSparkジョブと同等のものではないことにご注意ください。Talend Sparkジョブは、Talend Studioのワークスペースで行うTalendジョブのデザイン方法に応じて、Apache SparkでSparkジョブを1つまたは複数生成します。Sparkジョブに関する詳細は、Apache Sparkの公式のドキュメンテーションで用語集 (英語のみ)をご覧ください。
Talend Sparkジョブ内の各コンポーネントは、それぞれのミッションを達成するための特定のタスク(生成されたコード内のクラス)を生成する方法と、すべてのタスクを結合してジョブを形成する方法を把握しています。コンポーネント間の各接続は、データを含めることができる特定のストラクチャー(Avroレコード)を生成し、Sparkのシリアライズに対応しています。コンポーネントはそれぞれ特定のタスク向けに最適化されています。実行時には、生成されたこれらのクラスがデータを実行するノードに提供されます。ストラクチャーにはデータが含まれ、また、シャッフル段階でノード間に提供され、Talendジョブ自体が生成されたSparkジョブを調整します。
ジョブを実行する時に、ジョブのデザインワークスペースに統計情報が表示され、ジョブによって調整されているSpark計算の進行状況を示します。
次の図は、Talend Spark Batchジョブの例を示したものです。統計情報は緑色で表示されています。
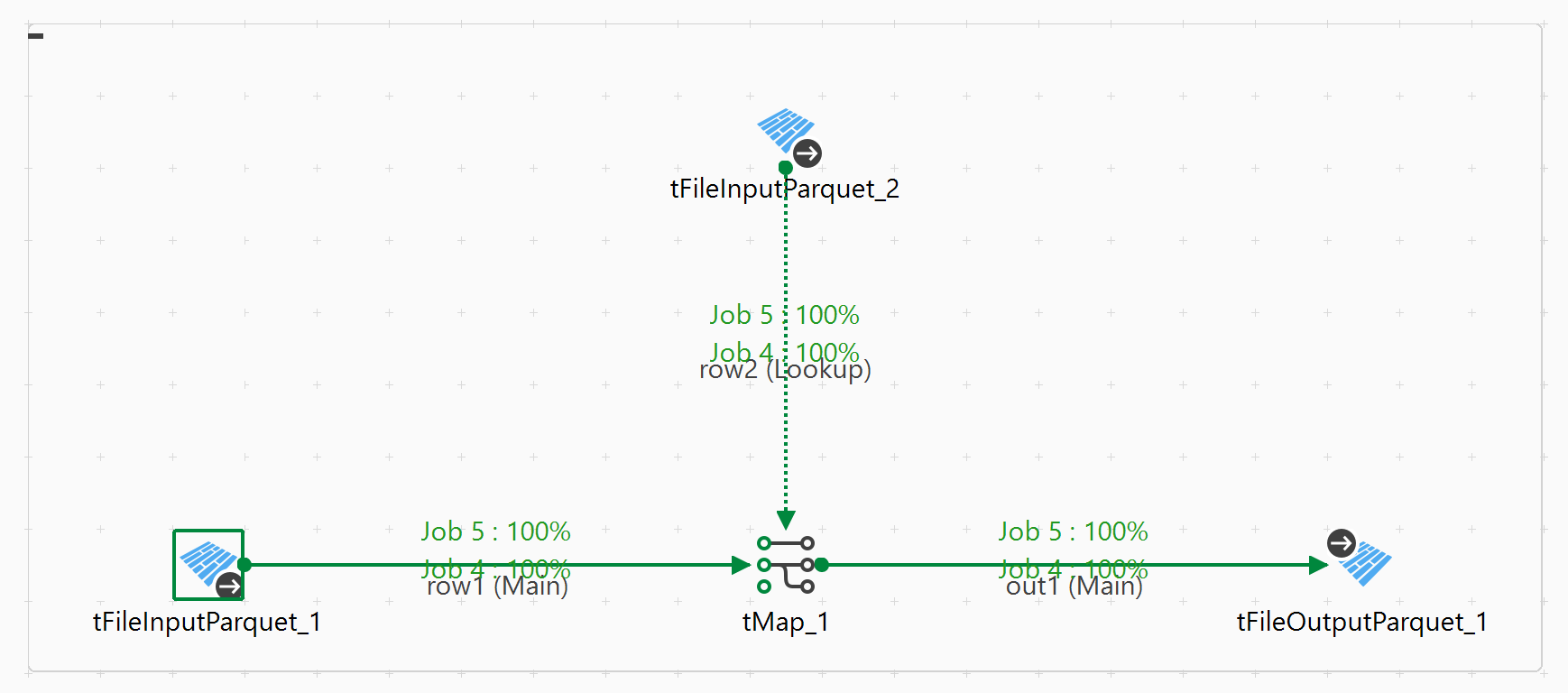
この例では、ジョブ4とジョブ5という2つのSparkジョブが作成されており、どちらも100%完了しています。
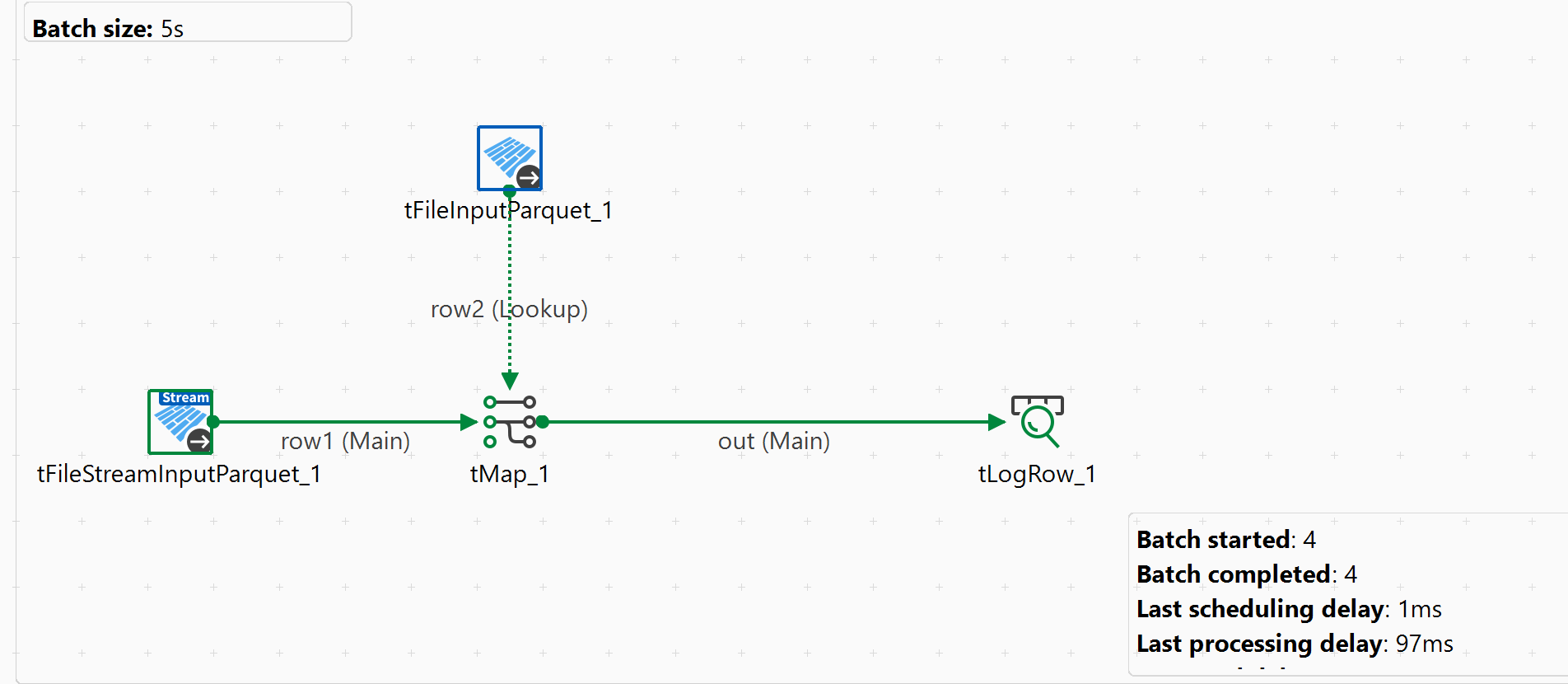
Talend Sparkジョブの実行情報は、使用しているクラスターのヒストリーサーバーサービスに記録されます。サービスのWebコンソールでその情報を調べることができます。コンソール内のジョブの名前はProjectName_JobName_JobVersionの形式で自動的に入力されます。たとえば、LOCALPROJECT_wordcount_0.1となります。