
Talend Big Dataのファンクションアーキテクチャー
Talend Big Dataファンクションアーキテクチャーは、Talend Big Data機能、相互作用、および対応するITニーズを特定するアーキテクチャーモデルです。アーキテクチャー全体は、特定の機能を機能ブロックに分離することで説明されています。
下の図は、主なアーキテクチャー機能ブロックを示しています。
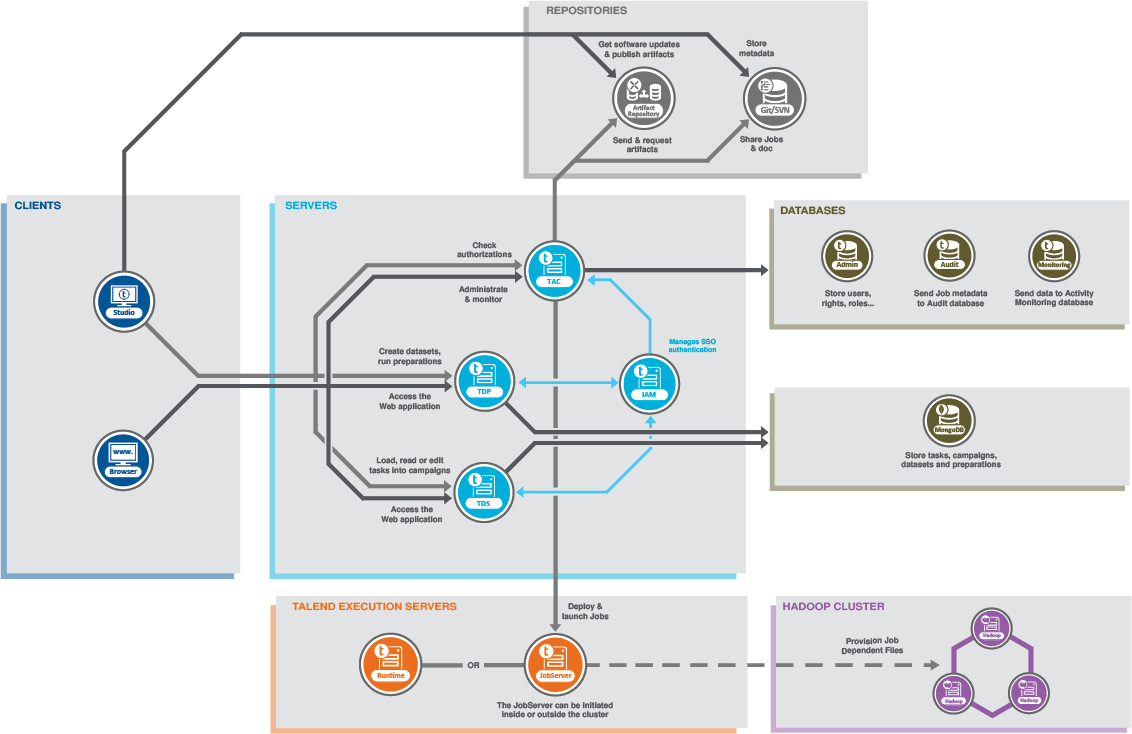
機能ブロックのタイプは以下のとおりです。
- Talend Studioから、Hadoopクラスターを活用するビッグデータジョブをデザインして起動し、大量のデータセットを処理します。これらのジョブは起動後にこのHadoopクラスターに送られ、そこでデプロイおよび実行されます。
- Talendシステムから独立したHadoopクラスターでは、大量のデータセットを処理します。
- ジョブをデプロイして実行するためにHadoopクラスターの中または外にインストールされたTalend JobServerまたはRuntime。
Hortonworksクラスターの場合は、ファイアウォールやアクセスの問題を回避できるよう、JobServerまたはRuntimeをエッジノードのマシンにインストールすることをお勧めします。
Amazon EMRクラスターの場合も、JobServerまたはRuntimeをクラスターにインストールすることをお勧めします。